научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 10, октябрь 2011
УДК 004.657
МГТУ им. Н.Э. Баумана
VPluzhnikov@croc.ru
Введение
В настоящее время возникает проблема, связанная с прогнозированием индексов производительности хранилищ данных, построенных на основе параллельных систем баз данных (ПСБД), т.к. соответствующие аппаратно-программные комплексы очень дороги и ошибки в их выборе приводят к большим финансовым потерям.
В предыдущей статье [4] рассмотрен математический метод анализа времени соединения таблиц в ПСБД. В данной работе демонстрируется применение математического аппарата производящих функций и преобразования Лапласа-Стилтьесадля оценки времени выполнения запросов к хранилищу данных в параллельной системе баз данных [11]. Этот метод учитывает особенности выполнения запросов к БД со схемой "звезда" в ПСБД, а также топологию (структуру) различных архитектурных решений.
Процесс выполнения запроса к хранилищу данных в параллельной системе баз данных
В современных параллельных системах баз данных [6] используется гибрид физической модели 3NF и многомерных представлений, поскольку системы очень хорошо обрабатывают соединения и обладают зрелым и надежным оптимизатором. Представления в ПСБД не материализуются до выполнения соответствующих запросов, что делает возможным отражать в плане запроса с соединением потребности каждого индивидуального запроса, минимизировать объем данных, которые требуется перераспределять или дублировать. Хэширование на первичном индексе упрощает разделение, и распределение памяти происходит только на уровне базы данных, а не на основе принципа таблица-раздел и индекс-раздел. В оптимизаторах ПСБД используется пересечение индексов, что обеспечивает эффективность почти такого же уровня, который дают битовые индексы, без потребности в накладных расходах для их поддержки. Это означает, что ПСБД нуждается в создании меньшего числа индексов, что приводит к дальнейшему сокращению требуемых объемов памяти и времени для поддержки индексов. Наличие возможности синхронного сканирования (sync scan) позволяет использовать время, требуемое для сканирования больших таблиц, для выполнения нескольких (и даже сотен и тысяч) параллельно выполняемых запросов, делающих одну и ту же работу, что повышает пропускную способность системы на несколько порядков.
Когда в 1988 г. фирма Teradata [5] впервые начала обслуживать сверхбольшие базы данных, обнаружились некоторые странные проблемы. Даже при использовании подхода с отказом от общих ресурсов (shared-nothing) для обработки и сканирования больших таблиц требуется большое время. В результате инженеры разработали методы, заставляющие оптимизатор сначала обрабатывать малые таблицы измерений, соединяя их с целью создания первичного индекса для большой таблицы фактов и сокращая тем самым время ответа для многих запросов. Эти методы были включены в оптимизаторы ПСБД.
Как показывает рис. 1, у большой таблицы (Sales) имеется составной первичный индекс, составленный из внешних ключей таблиц измерений Stores, Items и Weeks. В звёзднообразной схеме все четыре таблицы логически (а иногда и физически) объединяются. Запрос (SELECT), представленный на рис. 2, позволяет произвести выборку из Stores, Items и Weeks с пересечением с указанными данными из Sales. В частности, здесь необходимо узнать общий объем продаж всех телевизоров в некоторой группе штатов (скажем Colorado и Minnesota) в течение двух недель перед Super Bowl, и результаты запроса необходимо вывести в соответствии с размером экрана телевизора и в лексикографическом порядке названий магазинов. Указанное представление (View) эмулирует звезнообразную схему, в запросе не принимается во внимание базовая физическая модель, и запрос прост (особенности модели скрываются представлением).
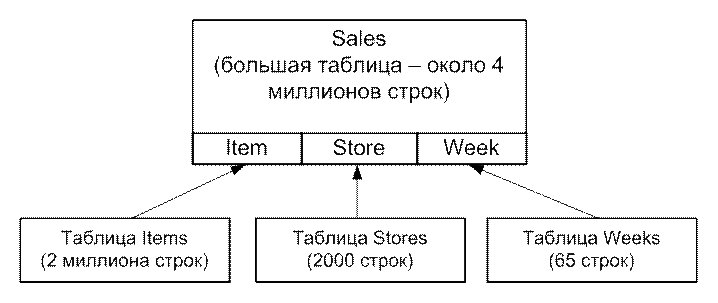
Рис. 1. Таблица Sales со звезднообразной схемой и составным первичным индексом.

Рис. 2. Запрос к таблице Sales..
Таблицы измерений и таблица фактов фрагментированы по АМР-процессам (АМР-процессорам) параллельной системы баз данных по значениям своих ключей. Таблица фактов фрагментирована по своему составному ключу, составленному из внешних ключей таблиц измерений. План выполнения запроса к хранилищу данных включает следующие шаги (рис. 3):
- Каждый AMP-процесс (Access Module Processes) производит выборку из таблицы Weeks по условию <Week selection criteria>. Промежуточный результат (Spool) дублируется на всех AMP (см. И1 на рис. 3).
- Все AMP производят выборку из таблицы Stores по условию <Store selection criteria>. Выполняется соединение со Spool по фиктивному условию (строится декартово произведение). Spool дублируется на всех AMP (см. И1×И2).
- Все AMP производят выборку из таблицы Items по условию <Item selection condition>. Выполняется соединение со Spool по фиктивному условию. Результат перераспределяется между всеми AMP и сортируется (см. И1×И2×И3)
- На всех AMP выполняется соединение Sales и Spool с использованием MERGE JOIN (сканирование строк с сопоставлением хэш-кодов).
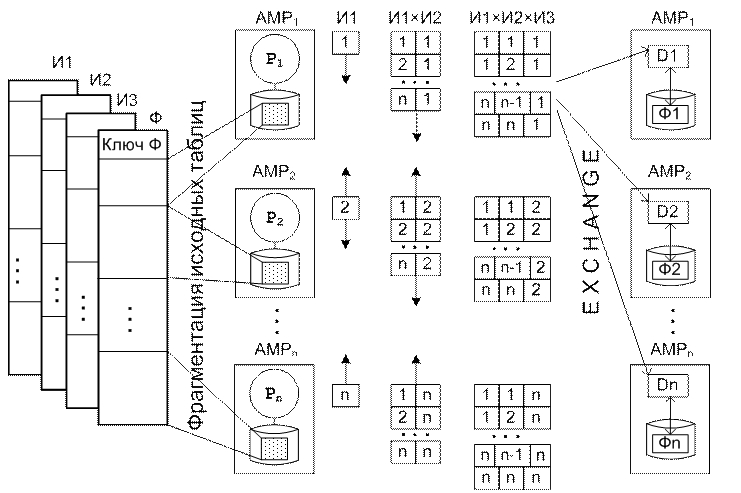
Рис. 3. Организация выполнения запроса к хранилищу данных в ПСБД.
Параллельные системы баз данных могут функционировать в многопроцессорных системах с разными архитектурными решениями [5]:
· архитектура SE (SMP) –системы, где ресурсы являются разделяемыми (дисковая подсистема, оперативная память, системная шина),
- кластерная архитектура SD- системы, в которых отсутствуют разделяемые ресурсы за исключением подсистемы дисковой памяти и соединительной шины,
· архитектура SN (MPP) – системы, где разделяется только шина, соединяющая узлы.
Ниже приводится преобразование Лапласа-Стилтьеса (ПЛС) времени выполнения запроса к хранилищу данных, которое справедливо для каждого АМР параллельной системы баз данных. Здесь используется математический аппарат, изложенный в работах [4, 8, 11].
Чтение данных измерений
Предполагается, что данные читаются по некластеризованному индексу. ПЛС времени поиска и чтения записей из таблиц измерений имеет следующий вид.
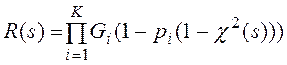 ,
, где
K – число измерений,
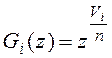 - производящая функция числа записей i-го измерения в узле,
- производящая функция числа записей i-го измерения в узле,
Vi – общее число записей i-го измерения,
n – число AMP- узлов (AMP-процессоров),
pi - вероятность, что запись i-го измерения удовлетворяет условию поиска по этому измерению в запросе,
χ2(s) - ПЛС времени обработки записи блока листового уровня индекса (χ(s)) и записи таблицы измерения (χ(s)),
Это ПЛС учитывает, что блок чередования, где хранится требуемая запись таблицы (или индекса), читается с диска (φD(s)), запись сохраняется и читается из ОП (![]() ), обрабатывается процессором (φPI(s)).
), обрабатывается процессором (φPI(s)).
Обмен записями таблиц измерений и декартова произведения между узлами
Введём следующие формулы.
![]() , (3)
, (3)
в этой формуле учитывается, что
каждая запись таблицы первого измерения рассматриваемого узла, удовлетворяющая условию поиска (p1), дублируется на другие узлы (![]() ),
),
записи, поступившие из других узлов, сохраняются в ОП и читаются в кэш процессора данного узла (![]() ),
),
каждая запись таблицы первого измерения, удовлетворяющая условию поиска, продублирована на каждом узле (zn); будем обозначать этот дубль через y1 (эта продублированная таблица одинакова на всех узлах).
![]() , (4)
, (4)
в этой формуле учитывается
процессорное время выполнения декартова произведения таблицы y1 и записей таблицы второго измерения рассматриваемого узла (φPJ(s)), удовлетворяющих условию поиска (p2),
чтение из ОП для сохранения записей декартова произведения в кэше процессора, а затем в ОП (![]() ),
),
что каждая запись декартова произведения рассматриваемого узла, дублируется на другие узлы (![]() ),
),
что записи декартова произведения, поступившие из других узлов, сохраняются в ОП и читаются в кэш процессора данного узла (![]() ),
),
что каждая запись декартова произведения продублирована на каждом узле, т.е. что записи поступили от других узлов (zn); будем обозначать этот дубль через y2 (эта продублированная таблица с результатами декартова произведения записей таблиц первых двух измерений одинакова на всех узлах).
И так далее получим
![]() ,
,
где
Ζ = (z1, ...,zn) – вектор,
функция ![]() - это производящая функция, которая определяет распределение одной записи полученного на данном узле декартова произведения записей таблиц измерений по другим узлам; распределение (межпроцессорный обмен) выполняет специальный оператор exchangeпо значениям составного ключа декартова произведения;
- это производящая функция, которая определяет распределение одной записи полученного на данном узле декартова произведения записей таблиц измерений по другим узлам; распределение (межпроцессорный обмен) выполняет специальный оператор exchangeпо значениям составного ключа декартова произведения; ![]() определяется следующими рекуррентными формулами:
определяется следующими рекуррентными формулами:
![]() ,
,
![]() ,
,
![]() ,
, ![]() ,
,
pj - это вероятность, что запись передаётся из данного узла в j-й узел при условии, что она не была передана в узлы n...j+1.
Поясним формулы (6). С вероятностью pn запись декартова произведения передаётся в n-й узел (испытание по схеме Бернулли успешно). С вероятностью (1 - pn) запись передаётся в другие узлы. Производящая функция числа таких записей равна ![]() и т.д. по рекурсии.
и т.д. по рекурсии.
Приведённая ниже формула определяет время пересылки промежуточных декартовых произведений измерений (s), время межпроцессорного обмена записями окончательного декартова произведения (φN(s)) и число записей таблицы фактов, обрабатываемых на данном (i-ом) узле (z):
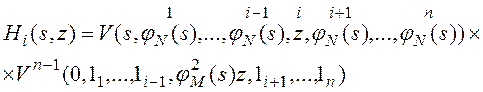
ПЛС ![]() учитывает, что поступившие в i-ый узел записи декартова произведения от других узлов сохраняются в ОП и читаются в кэш процессора.
учитывает, что поступившие в i-ый узел записи декартова произведения от других узлов сохраняются в ОП и читаются в кэш процессора.
ПЛС времени выполнения запроса к ROLAPв ПСБД
Это ПЛС имеет следующий вид
R(s) определяется выражением (1), Hi(s, ×) – выражением (7), χ(s) – определяется выражением (2), φPA(s) – ПЛС времени, затраченного узлом на агрегирование факта одной записи, φPS(s) – ПЛС времени сортировки на одно сравнение в ОП.
Таблица 1
| SE | SD | SN |
φD(s) |
|
| |
φM(s) |
(обмен между процессорами осуществляется через ОП) |
| |
φN(s) |
| ||
φPI(s), φPJ(s), φPA(s), φPS(s) |
| ||
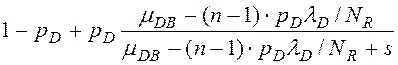
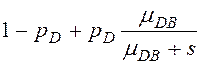
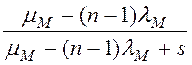
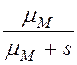
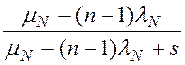
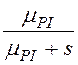 ,
, 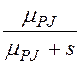
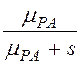 ,
, 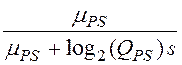
В табл. 1 приведены выражения для ПЛС φD(s), φM(s), φN(s), φPI(s), φPJ(s), φPA(s), φPS(s) – это ПЛС случайного времени обработки записи (исходной, промежуточной, результирующей) в ресурсе (диске, ОП, шине, процессоре),
1-pD – вероятность, что запись находится в кэше (СУБД или диска),
λD, λM, λN– интенсивности запросов к разделяемому ресурсу (на чтение записей из RAID-массива, на запись/чтение записей таблиц из ОП, на передачу записей по соединительной шине),
μDB=1/tБЧ – интенсивность чтения блоков чередования с диска RAID-массива, tБЧ - среднее время чтения блока чередования,
NR – количество дисков в RAID-массиве (с учётом зеркальных),
μM – интенсивность записи/чтения записей таблиц из ОП,
μN – интенсивность передачи записей по соединительной шине,
μPI– интенсивность обработки записей в процессоре при их поиске и чтении с помощью индекса,
μPJ– интенсивность построения записей декартова произведения в процессоре,
μPS– интенсивность сравнений записей БД в процессоре при их сортировке,
μPA– интенсивность агрегации записей (значений фактов),
QPS– значение коэффициента при среднем значении . ![]() (см. ниже),
(см. ниже),
(n-1) в табл. 1 означает, что заявка не ждёт сама себя в очереди к ресурсу.
Таким образом, в статье приведён вывод преобразования Лапласа-Стилтьеса случайного времени выполнения запроса к хранилищу данных для различных архитектур: SE (SMP), SD(кластер), SN(MPP), смешанной архитектуры на основе SMP-узлов. Это преобразование позволяет оценивать моменты случайного времени разных порядков (математическое ожидание, дисперсию и т.д.).
ЛИТЕРАТУРА
1. М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных: [Электронный ресурс]. [http://citforum.ru/database/classics/distr_and_paral_sdb/]. Проверено 26.11.2010.
2. Соколинский Л. Б., Цымблер М. Л. Лекции по курсу "Параллельные системы баз данных”: [Электронный ресурс]. [http://pdbs.susu.ru/CourseManual.html]. Проверено 04.12.2010.
3. Дж. Льюис. Oracle. Основы стоимостной оптимизации. – СПб: Питер, 2007. – 528 с.
4. Григорьев Ю.А., Плужников В.Л. Оценка времени соединения таблиц в параллельной системе баз данных// Информатика и системы управления. – 2011. - № 1. – С. 3-16.
5. Лисянский К., Слободяников Д. СУБД Teradata® для ОС UNIX®: [Электронный ресурс]. [http://citforum.ru/database/kbd98/glava5.shtml]. Проверено 14.03.2011.
6. КузнецовС. Essential Modelling Options: [Электронныйресурс]. [http://citforum.ru/database/digest/dig_1612.shtml]. Проверено 14.03.2011.
7. Лев Левин. Teradata совершенствует хранилища данных: [Электронный ресурс]. [http://www.pcweek.ru/themes/detail.php?ID=71626]. Проверено 26.11.2010.
8. Григорьев Ю.А., Плутенко А.Д. Теоретические основы анализа процессов доступа к распределённым базам данных. - Новосибирск: Наука, 2002. – 180 с.
9. Форум/Использование СУБД/Oracle/CPUSPEED на IntelXeon 5500 (Nehalem): [Электронный ресурс]. [http://www.sql.ru]. Проверено 02.12.2010.
10. Миллер Р., Боксер Л. Последовательные и параллельные алгоритмы. Общий подход. – М.: БИНОМ. Лаборатория знаний, 2006. – 406 с.
11. Григорьев Ю.А., Плужников В.Л. анализ времени обработки запросов к хранилищу данных в параллельной системе баз данных // Информатика и системы управления. – 2011. - № 2. – С. 94-106.
Публикации с ключевыми словами: преобразование Лапласа-Стилтьеса в параллельной системе базы данных, время обработки запросов, архитектура параллельной системы базы данных
Публикации со словами: преобразование Лапласа-Стилтьеса в параллельной системе базы данных, время обработки запросов, архитектура параллельной системы базы данных
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||