научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 03, март 2010
УДК. 004.82
МГТУ имени Н.Э. Баумана
d-eli@mail.ru
Введение
Большинство автоматизированных информационных систем работают по жёстко запрограммированным алгоритмам. Но существуют такие предметные области и задачи автоматизации, в которых использование данного принципа создания автоматизированной системы не является оптимальным. Как правило, данные предметные области (задачи автоматизации) имеют сложную структуру, которую трудно алгоритмизировать. В них происходят частые изменения, которые могут затрагивать как бизнес-процессы, так и значения некоторых данных, участвующих при выработке решений. Поэтому при необходимости изменить какой-либо бизнес-процесс системы нужно прибегать к помощи программистов, которым приходится анализировать большие объёмы кода, даже если эти изменения несущественны. Примерами таких предметных областей могут служить области, связанные с системой управления вузом [1, 2], системой управления персоналом, экономикой и т.д.
В предметных областях, которые постоянно развиваются, возникает потребность в адаптивных информационных системах. Адаптивные информационные системы должны удовлетворять двум главным требованиям:
a) адекватно отражать знания о предметной области в каждый момент времени;
b) быть пригодными для лёгкой и быстрой реконструкции при изменении предметной области [3].
Адаптивные свойства информационных систем обеспечиваются за счёт интеллектуализации их архитектуры. Ядром таких систем является постоянно развиваемая модель предметной области, поддерживаемая в специальной базе знаний.
Таким образом, при разработке адаптивной информационной системы целесообразно разделить её функции на два типа:
a) функции, которые легко алгоритмизировать (обработка и отображение данных);
b) функции, которые можно отнести к интеллектуальным (функции принятия решений).
В соответствии с этим, адаптивную информационную систему можно разделить на две части:
a) подсистема обработки, хранения и отображения данных;
b) интеллектуальная подсистема.
В результате адаптивная информационная система имеет две независимые подсистемы, которые взаимодействуют друг с другом.
Преимущество такой адаптивной информационной системы состоит в том, что можно редактировать базу знаний и влиять на работу системы в целом (изменять критические алгоритмы или данные, которые участвуют при выборе решения). Структура интеллектуальной части системы является универсальной и не зависит от её наполнения. Следовательно, эту часть системы можно использовать в разных адаптивных информационных системах без каких-либо изменений.
1 Структура адаптивной информационной системы
Структура адаптивной информационной системы представлена на рис. 1.
Подсистема обработки данных состоит из базы данных и приложения, взаимодействующего с ней. Приложение взаимодействует также с пользователем, получая от него команды, и запускает соответствующие процессы по обработке данных, которые содержат обращения к интеллектуальной подсистеме. Приложение взаимодействует с интеллектуальной подсистемой, когда необходимо выполнить действие, связанное с принятием определённого решения, или необходимо получить информацию, хранящуюся в базе знаний.
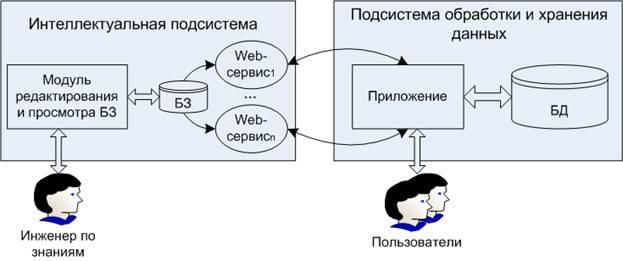
Рис.1. Структура адаптивной информационной системы
Приложение вызывает соответствующий Web-сервис и передаёт ему данные, описывающие текущее состояние системы, и запрос, который должна выполнить интеллектуальная подсистема. С помощью Web-сервисов реализуется механизм логического вывода, а каждый Web-сервис реализует решение определённого класса задач. Web-сервис ищет решение (ответ на запрос) на основе входных данных и информации, хранящейся в базе знаний. Затем, ответ передаётся приложению, которое использует его для дальнейшего выполнения процесса обработки данных.
Преимуществом Web-сервисов является то, что они позволяют использовать различные средства для разработки приложения и базы данных. В этом случае интеллектуальная подсистема не зависит от практической реализации подсистемы обработки и хранения данных, т.к. обмен информацией между ними происходит с использованием языка XML, который в настоящее время широко используется для интеграции разнородных систем.
На схеме, представленной на рис. 1, база знаний представляет собой специально спроектированную базу данных. В ней хранится информация о фактах и правилах предметной области, а также структурная информация, описывающая интерпретацию фактов.
Заполняется и редактируется база знаний через «Модуль редактирования и просмотра БЗ». Через этот модуль осуществляется доступ к БЗ инженера по знаниям. Также в функции данного модуля входит контроль непротиворечивости системы правил и контроль правильности ввода новых знаний.
2 Выбор модели представления знаний
Выбор способа представления знаний в интеллектуальной системе является ключевым моментом разработки. С точки зрения человека, желательно, чтобы описательные возможности используемой модели были как можно выше. С другой стороны, сложное представление знаний требует специальных способов обработки (усложняется механизм вывода), что затрудняет проектирование и реализацию интеллектуальной подсистемы [3].
Существуют четыре основные модели описания знаний: логические модели, сетевые модели, продукционные модели и фреймовые модели. Каждая из этих моделей имеет свои достоинства и недостатки.
Сетевая модель является наиболее общей моделью представления знаний. Но такая универсальность имеет и негативную сторону. Если допускать в сетевой модели произвольные типы отношений и связей, не являющихся отношениями в математическом смысле (например, ассоциативные связи), то резко возрастает сложность работы с такой моделью [4]. Также построение сетевой модели зависит от взгляда на проблему самого разработчика. Поэтому разные инженеры по знаниям могут спроектировать разные модели одной предметной области, что может сказываться негативно на реализации процедур обработки знаний.
Во фреймовых моделях соединены основные особенности моделей перечисленных типов. Но в отличие от них, во фреймовых моделях фиксируется жёсткая структура информационных единиц [4]. Это существенно снижает гибкость такой модели.
Логические модели предназначены для использования в исследовательских системах, и основной их задачей является доказательство теорем и организация вывода в логике. К недостатку этих моделей относится то, что они предъявляют высокие требования к качеству и полноте знаний о предметной области [3].
Продукционные модели наряду с фреймами являются наиболее популярными средствами представления знаний. Продукции, с одной стороны, близки к логическим моделям, что позволяет организовать на них эффективные процедуры вывода, а с другой стороны, отражают знания более наглядно, чем классические логические модели [5].
Продукционные модели имеют, по крайней мере, два недостатка. При большом числе продукций становится сложной проверка непротиворечивости системы правил. Это заставляет при добавлении новых продукций тратить много времени на проверку непротиворечивости полученной системы. Из-за присущей системе недетерминированности (неоднозначного выбора выполняемой продукции из множества активизированных продукций) возникают принципиальные трудности при проверке корректности работы системы [4].
Каждой модели представления знаний отвечает свой язык. Однако на практике при разработке системы редко удаётся обойтись рамками одной модели представления знаний за исключением самых простых случаев [3].
Для реализации базы знаний адаптивной информационной системы можно выбрать сочетание продукционной и логической моделей. Совместное использование этих моделей представления знаний обладает рядом преимуществ:
a) снижаются требования к качеству и полноте хранящихся знаний;
b) увеличивается эффективность обработки продукций;
c) увеличивается наглядность представления знаний, т.к. подавляющая часть человеческих знаний может быть записана в виде продукций.
3 Структура базы знаний, использующая логическую и продукционную модели
3.1 Логическая структура базы знаний
Логическая структура базы знаний, использующая логическую и продукционную модели, приведена на рис.2.
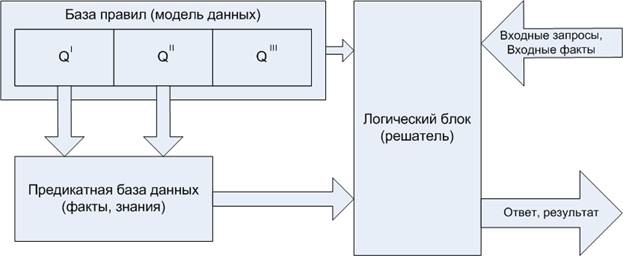
Рис.2. Логическая структура базы знаний, использующая логическую и продукционную модели
В базе знаний можно выделить три основные части:
a) база правил;
b) предикатная база данных;
c) логический блок.
Для описания базы правил или модели данных воспользуемся следующими понятиями.
Классам сущностей предметной области отвечают сорта (или типы), т.е. имена сортов интерпретируются как классы сущностей
Сигнатурой называется множество S выражений вида
![]() (1)
(1)
где Aj, B – сорта, а f – функция.
Сигнатура задаёт структурные связи между понятиями предметной области, представленные предикатами и функциями. Логические связи между этими понятиями задаются формулами в этой сигнатуре (интерпретирующая сигнатуру структура). Структурные и логические связи выражают некоторое знание о предметной области.
Таким образом, все формулы строятся на основе сигнатуры S. Произвольная формула составляется из атомарных формул (атомов) с использованием логических связок ù, Ù. Ú, ® и кванторов " и $. Атомы составляются из термов (переменная, принимающая значение из сорта А), предикатных символов и символа равенства. Всякая входящая в атом переменная считается свободной в этом атоме. Если при составлении формулы используются кванторы, то переменные, с которыми они используются, считаются связанными.
Пусть Q – логическая модель предметной области. Тогда Q состоит из двух частей: Qï и Q| |, которые описывают соответственно структурные свойства предметной области и логические её свойства. В нашем случае Qï есть сигнатура S, а Qïï есть совокупность замкнутых формул (т.е. формулы, не включающие свободные переменные), записанных в сигнатуре S. Часть Qïï служит для представления ограничений, которым удовлетворяют сущности и отношения предметной области, закономерностей, описывающих поведение сущностей [4].
Если из Qïï отдельно записать правила, по которым можно проверять истинность новых утверждений, то можно предложить разбиение логической модели предметной области Q на три части: Qï, Qïï и Qïïï. При этом в Qïï останется описание только ограничений, которым удовлетворяют сущности и отношения предметной области, а в Qïïï мы будем записывать продукционные правила.
Предикатная база данных (рис. 2) хранит факты о предметной области (атомарные константные формулы), которые используются системой продукций Qïïï. Набор типов фактов определяется Qï, а правильность их написания – Qïï. Факты отражают знания эксперта о предметной области, которые всегда являются истинными, как правило, это какие-либо постоянные связи или значения термов.
Логический блок содержит основные алгоритмы работы с фактами и правилами, а также механизмы логического вывода и средства взаимодействия с внешним миром. Данный блок принимает входные факты и запросы, проверяет, соответствуют ли переданные факты хранящейся в базе знаний логической модели предметной области, осуществляет логический вывод, исходя из входного запроса, а также формирует результат выполнения этого запроса.
3.2 Структура продукционных правил
В общем виде под продукцией понимается выражение следующего вида:
![]()
Здесь i – имя продукции, с помощью которого данная продукция выделяется из всего множества продукций. В качестве имени может выступать некоторая лексема, отражающая суть данной продукции, или порядковый номер продукции в их множестве. На основании имени можно строить деревья вывода.
Элемент E характеризует сферу применения продукции. Такое разделение правил похоже на запоминание человеком информации. Наши знания, как бы «разложены по полочкам». Разделение знаний на отдельные сферы позволяет экономить время на поиск нужной продукции.
Основным элементом продукции является её ядро: А Þ В (ЕСЛИ А ТО В). Продукция может истолковываться в обычном логическом смысле как знак логического следования В из истинного А (если А не является истинным выражением, то о В ничего сказать нельзя). Но в нашей базе знаний интерпретация ядра продукции является следующей: А описывает некоторые условия, необходимые для того, чтобы можно было совершить В.
Элемент Р есть условие применимости ядра продукции. Обычно Р представляет собой логическое выражение, как правило, предикат. Когда Р принимает значение «истина», ядро продукции активизируется. Если Р ложно, то ядро продукции не может быть использовано.
Элемент N описывает постусловия продукции. Они актуализируются только в том случае, если ядро продукции реализовалось. Постусловия продукции описывают действия, которые необходимо выполнить после реализации [4, 7].
3.3 Пример описания базы правил и предикатной базы данных
Рассмотрим описание логической структуры базы знаний в предметной области, связанной с управление персоналом. Возьмём задачу определения размера ставки, на которую можно принять работника.
Пусть Qï имеет описание, представленное в формуле (2).
|
|
(2) |

Если использовать аналогию с описанием баз данных, то Qï соответствует описанию таблиц базы данных.
Формула (2) означает, что в нашей базе знаний используются два типа фактов: вид_работы_ставка (задаёт зависимость между видом работы и размером ставки) и вход_данные_работника_ставка (задаёт структуру фактов, которые будут поступать в систему как входные данные, рис. 2).
Тогда Qïï представлено в формуле (3).
![]()
Предложение (3) выражает то, что (Вид_работы, Доп_сведения), взятые вместе, являются ключом отношения вид_работы_ставка в формуле (2). Если использовать аналогию с описанием баз данных, то Qïï соответствует описанию функциональных зависимостей отношений, записанных в Qï.
При описании Qïï использовался синтаксис языка логического программирования Пролог. Согласно этому синтаксису имена отношений, функций и констант пишутся малыми буквами, а имена переменных начинаются с заглавных букв. Знак :- является символом импликации, но записанной справа налево (¬); запятая служит символом конъюнкции [5, 6]. Предложение (3) является примером правила. В правилах неявно предполагается, что все переменные связаны квантором ".
Предложения пролога состоят из головы (В) и тела (А), А®В. Тело – это список целей, разделённых логической связкой. Также в Прологе предложения бывают трёх типов: факты, правила и вопросы.
Факты содержат утверждения, которые являются всегда безусловно верными. Они имеют пустое тело.
Правила содержат утверждения, истинность которых зависит от некоторых условий. Правила имеют голову и (непустое) тело.
С помощью вопросов пользователь может спрашивать систему о том, какие утверждения являются истинными. Вопросы имеют только тело [5, 6].
Qï и Qïï вместе предоставляют средства для описания логической модели предметной области, хранимой в базе знаний. Используя их, можно осуществлять проверку правильности введения новых фактов в базу знаний.
На основе описания Qï и Qïï заполним предикатную базу данных следующими фактами (4).
|
|
(4) |

Таким образом, в предикатной базе данных (рис. 2) находятся пять фактов. Одинарные кавычки означают, что данное выражение является атомом (значением из множества «Вид_работы»).
Теперь опишем систему правил Qïïï. Для простоты правила будут иметь вид А®В:
|
|
(5) |
|
|
(6) |
|
|
(7) |
|
|
(8) |
|
|
(9) |
|
|
(10) |
|
|
(11) |
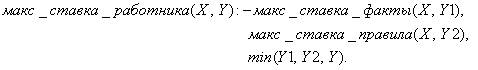
Формула (5) означает, что для всех X и Y, Y является максимальной ставкой работника X, если Y1 – максимальная ставка работника X по базе фактов и Y2 – максимальная ставка работника X по базе правил и Y равен минимальному значению из Y1 и Y2.
Формула (6) означает, что для всех X и Y1, Y1 является максимальной ставкой по базе фактов для работника X, если Y1 является максимальной ставкой по виду работы B и дополнительным сведениям D из входных данных работника. Остальные правила интерпретируются аналогично правилам (5) и (6).
Правила (10) и (11) определяют минимальное значение из Y1 и Y2, причём в зависимости от ситуации срабатывает только одно из этих правил.
Итак, пусть на вход системы поступает входной факт (12) и запрос (13).
|
|
(12) |
|
|
(13) |
Входной факт (12) передаёт в интеллектуальную подсистему данные, которые находятся в приложении (рис.1). Этот факт является дополнением к фактам, хранящимся в предикатной базе данных (рис. 2).
3.4 Работа логического блока при решении задачи
Вычисление запроса инициируется формулой (13), которая формирует цель: «Найти факт, унифицируемый с макс_ставка_работника(X,Y)». Логический блок (рис. 2) для достижения поставленной цели предпринимает следующие шаги.
Шаги вычисления.
1) Искомый список целевых утверждений: макс_ставка_работника(X, Y).
2) Логический блок ищет в базе знаний предложение, у которого голова сопоставима с целевым утверждением. Поиск начинается с предикатной базы данных, а затем переходит к базе правил. В результате логический блок находит правило (5). После этого происходит замена списка целевых утверждений телом правила (5). Таким образом, порождается новый список целевых утверждений.
макс_ставка_факты(X,Y1),
макс_ставка_правила(X,Y2),
min(Y1,Y2,Y).
3) Затем происходит просмотр базы знаний для нахождения предложения, сопоставимого с макс_ставка_факты(X,Y1). Найдено правило (6). В результате появляются две новых цели.
вход_данные_работника_ставка(X,_, B, D),
вид_работы_ставка(В, Y1, D).
4) Далее происходит поиск предложения
вход_данные_работника_ставка(X,_,B,D), которое найдено во входном факте (12). В результате получаем следующую конкретизацию: X=’Иванов И.И.’, B=’основная работа’, D=’студент’. Т.к. у данного предложения нет тела, то логический блок переходит к шагу 3 и ищет следующую цель - вид_работы_ставка(’основная работа’,Y1, ’студент’).
5) Цель вид_работы_ставка(’основная работа’,Y1, ’студент’) логический блок находит в предикатной базе данных, откуда получает значение для Y1=0.50. Возвращаясь к шагу 3, получаем истинное значение предиката макс_ставка_факты(X,Y1), если X=’Иванов И.И.’ и Y1=0.50.
6) Рассматриваем следующее целевое утверждение
макс_ставка_правила(’Иванов И.И.’,Y2). Логический блок находит правило (7). Но, анализируя правило (7), логический блок обнаруживает, что условие O<16 не выполняется, т.к. O=20, поэтому логический блок ищет следующее правило для рассматриваемой цели. Находит правило (8), которое также не подходит. Затем логический блок находит правило (9). В данном правиле выполняются два условия, и переменная Y2 приобретает значение 1.00. Таким образом, предикат макс_ставка_правила(’Иванов И.И.’,Y2) принимает истинное значение, если Y2=1.00. Опять возвращаемся к шагу 3 и рассматриваем последнее целевое утверждение.
7) Для целевого утверждения min(0.50,1.00,Y) логический блок находит правило (10). Т.к. условие Y1£Y2 выполняется, то переменной Y будет сопоставлено значение 0.50. Таким образом, утверждение min(0.50,1.00,Y) будет истинно при Y=0.50.
8) Возвращаясь к шагу 1, мы получаем истинное значение предиката макс_ставка_работника(X, Y) при X=’Иванов И.И.’ и Y=0.50. Эти значения и будут ответом на запрос.
В результате логический блок передаёт вызвавшему его приложению следующий результат: макс_ставка_работника(’Иванов И.И.’, 0.50).
В данном примере подбор правил и фактов для решения поставленной задачи выявил только одно возможное решение. В общем случае решений может быть несколько. Поэтому, когда интерпретатор ищет в базе знаний соответствующее предложение, после первой успешной конкретизации переменных и получения результата необходимо вернуться к дальнейшему поиску и просмотру базы знаний до конца. В результате в нашем примере база знаний просматривалась целиком неоднократно. Для уменьшения затрат времени на поиск нужных фактов логический блок должен сначала анализировать структуру Qï, а только затем обращаться непосредственно к предикатной базе. Для уменьшения времени просмотра правил нужно использовать структуру продукций, приведённую выше.
Заключение
В данной статье рассмотрена структура адаптивной информационной системы. Основным элементом такой системы является база знаний, которая взаимодействует с подсистемой обработки и хранения данных. Преимуществом адаптивной информационной системы является то, что при редактировании базы знаний инженер по знаниям влияет на выполнение системой бизнес-процессов. В результате система становится более гибкой и способной адаптироваться к специфике работы пользователей.
Структура интеллектуальной подсистемы, в первую очередь, зависит от выбора модели представления знаний. Для реализации базы знаний адаптивной информационной системы выбрано сочетание продукционной и логической моделей. Такое представление знаний обладает рядом преимуществ: снижает требования к качеству и полноте хранящихся знаний, увеличивает эффективность обработки продукций и повышает наглядность представления знаний.
Таким образом, возможности применения адаптивной информационной системы не будут ограничены одной предметной областью. В зависимости от заполнения интеллектуальной части знаниями, её можно использовать в разных предметных оластях.
Список литературы
1. Информационная управляющая система МГТУ им. Н.Э. Баумана «Электронный университет»: концепция и реализация / Т.И. Агеева, А.В. Балдин, В.А. Барышников и др.; [под ред. И.Б. Фёдорова, В.М. Черненького]. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2009. – 376 с.
2. Информационные технологии в инженерном образовании / под ред.С.В. Коршунова, В.Н. Гузненкова. – М.: Изд-во МГТУ им. Н.Э. Баумана, 2007. – 432 с.
3. Андрейчиков А.В., Андрейчикова О.Н. Интеллектуальные информационные системы. – М.: Финансы и статистика, 2004. – 424 с.
4. Искусственный интеллект. – В 3-х кн. Кн. 2. Модели и методы: Справочник/ Под ред. Д.А. Поспелова – М.: Радио и связь, 1990. – 304 с.
5. Братко И. Программирование на языке Пролог для искусственного интеллекта: Пер. с англ. – М.: Мир, 1990. – 560 с.
6. Адаменко А.Н., Кучуков А.М. Логическое программирование и Visual Prolog. – СПб.: БХВ-Петербург, 2003, 992 с.
7. Нильсон Н. Принципы искусственного интеллекта: Пер. с англ. – М.: Радио и связь, 1985. – 376 с.
Публикации с ключевыми словами: продукция, база знаний, адаптивная система, модель представления знаний
Публикации со словами: продукция, база знаний, адаптивная система, модель представления знаний
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||