научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 01, январь 2013
DOI: 10.7463/0113.0525190
УДК 519.6
Россия, МГТУ им. Н.Э. Баумана
Введение
В настоящее время вычислительная гидродинамика находит широкое применение при решении, например, задач авиа-, судо- и двигателестроения. В силу высокой вычислительной сложности методов этой науки для решения указанных и других задач используют параллельные вычислительные системы различных классов и, прежде всего, кластерные системы. Для уменьшения расходов на вычисления в настоящее время в качестве альтернативы кластерам все чаще используют графические процессорные устройства (ГПУ). Статья подготовлена в рамках работ по адаптации программного комплекса FlowVision [1] российской компании «Тесис» к ГПУ.
На верхнем иерархическом уровне рассматриваемая в работе задача представляет собой задачу течения жидкости или газа в некотором заданном объеме. Имеется в виду, что для описания течения используются математически модели, основанные на дифференциальных уравнениях в частных производных (ДУЧП) Навье-Стокса, Эйлера, Рейнольдса и т. д. Для численного решения этих уравнений чаще всего применяют методы конечных разностей (КР), конечных элементов (КЭ) и конечных объемов (КО).
При использовании регулярной сетки метод КР прост в реализации, эффективен, имеет наглядную процедуру дискретизации и позволяет легко получить высокий порядок точности. Существенным недостатком метода является то, что его достоинства проявляются только при использовании регулярной сетки, которая возможна лишь в случае простой геометрии расчетной области [2]. К достоинствам метода КЭ относится простота использования его для задач с произвольной формой области решения, к недостаткам — высокая вычислительная и алгоритмическая сложность [2].
И метод КР и метод КЭ обладают еще тем недостатком, что обычно не обеспечивают в явном виде выполнения законов сохранения [3]. От этого недостатка свободен метод КО [3]. По сравнению с методов КР, метод КО обладает более высокими возможностями использования в областях произвольной формы, а по сравнению с методом КЭ – меньшими вычислительными затратами. На этом основании в программном комплексе FlowVision применяется именно метод КО.
Численное решение краевых задач для ДУЧП является весьма ресурсоемкой задачей. Так, например, современные практически значимые задачи гидрогазодинамики требуют использования неструктурированных адаптивных расчетных сеток с числом ячеек порядка 100 млн. Поэтому одним из главных направлений развития FlowVisionявляется повышение эффективности использования вычислительных ресурсов.
В настоящее время FlowVision ориентирован на кластерные вычислительные системы, процессоры которых являются многоядерными [1]. На каждом процессоре кластера FlowVision запускает один процесс, использующий библиотеки IntelTBB и OpenMP для создания некоторого динамически определяемого числа потоков (threads). Обмен данными между этими потоками происходит через общую память процессора. Обмен данными между процессами, запущенными на разных процессорах, реализуется с помощью библиотека MPI.
В связи с тем, что в настоящее время идет активное внедрение гетерогенных кластерных вычислительных систем, в состав которых входят ГПУ, все более актуальной становится задача адаптации программного обеспечения и, в частности, FlowVision, к таким системам. Решение этой задачи, с одной стороны, может дать заметный выигрыш в производительности, с другой стороны, сложная многоуровневая гибридная архитектура таких вычислительных систем приводит к значительному усложнению программного обеспечения.
Современными производителями ГПУ являются, прежде всего, компании AMD и NVIDIA. Основу ГПУ обоих производителей составляет набор SIMD узлов (потоковых мультипроцессоров), связанных разделяемой памятью [4]. Каждый из потоковых мультипроцессоров включает в себя несколько потоковых процессоров, блок специализированных АЛУ, обеспечивающих вычисление наиболее часто встречающихся математических функций, блок вычислений с двойной точностью, разделяемую память и т.д.
Программирование ГПУ обеих указанных компаний осуществляют с помощью универсальной технологии OpenCL [5] и технологии CUDA [6], разработанной компанией NVIDIA для ее собственных ГПУ. Несмотря на универсальность технологии OpenCL, работа ориентирована на использование ГПУ NVIDIA и технологии CUDA. Данный выбор обусловлен следующими соображениями:
‑ неполная на момент начала работы поддержка обоими производителями стандарта OpenCL;
‑ более интенсивное развитие технологии CUDA по сравнению с технологией OpenCL;
‑ наличие у авторов опыта работы с технологией CUDA.
Компания NVIDIA предоставляет библиотеку cuBLAS, реализующую некоторые алгоритмы линейной алгебры [7]. Например, библиотека поддерживает умножение матрицы на матрицу, матрицы на вектор и т.д. Однако библиотека ориентирована только на операции с плотными матрицами и поэтому не может быть использована в нашем случае. Для работы с разреженными матрицами предназначена ориентированная на ГПУ библиотека cuSPARSE [8], но в этой библиотеке в настоящее время реализована операция умножения блочно-разреженной[<анонимны1] матрицы только на один вектор, в то время как в FlowVision требуется умножение такой матрицы на набор векторов.
В первом разделе работы представлена постановка задачи. Во втором разделе обсуждаем алгоритм неполных треугольных факторизаций второго порядка точности ILU2, распараллеливанию которого и посвящена работа. В третьем разделе рассматриваем алгоритмическую и программную реализации на ГПУ двух основных операций алгоритма ILU2 – операция умножения матрицы на блок векторов и операция решения блочно-треугольной системы линейных алгебраических уравнений (СЛАУ). В четвертом разделе представлены результаты исследования эффективности принятых алгоритмических и программных решений. В заключении сформулированы основные результаты работы и перспективы ее развития.
1 Постановка задачи
FlowVision позволяет производить полный комплекс действий для расчёта 3Dстационарных и нестационарных течений газов и жидкостей в областях произвольной сложной формы с учетом теплообмена и химических реакций:
‑ импорт геометрической модели;
‑ автоматизированное построение расчетной сетки на основе модели;
‑ задание начальных и граничных условий;
‑ формирование математической модели в виде СЛАУ на основе метода КО;
‑ решение указанной СЛАУ;
‑ визуализация результатов моделирования.
Комплекс использует адаптивную локально измельчаемую расчетную сетку с прямоугольными ячейками и с подсеточным разрешением геометрии [9]. Последний механизм позволяет аппроксимировать криволинейные границы без измельчения сетки и основан на том, что ячейка, через которую проходит граница, разбивается на несколько ячеек, часть из которых исключается из расчета. Оставшиеся ячейки представляют собой не прямоугольные параллелепипеды, а многогранники произвольной формы. Важно, что уравнения математической модели для этих многогранников FlowVision аппроксимирует без упрощений, что позволяет рассчитывать течения с высокой точностью даже на грубой сетке.
Метод КО, в конечном счете, сводит решение модельной краевой задачи для ДУЧП к решению СЛАУ вида
![]() , (1)
, (1)
где А ‑ ![]() -разреженная квадратная матрица,
-разреженная квадратная матрица, ![]() ‑
‑ ![]() -вектор правой части,
-вектор правой части, ![]() ‑ искомый
‑ искомый ![]() -вектор решения. Особенностями СЛАУ (1) являются высокая размерность и возможная плохая обусловленность.
-вектор решения. Особенностями СЛАУ (1) являются высокая размерность и возможная плохая обусловленность.
Для решения СЛАУ разработано большое число различных методов, наиболее простыми из которых являются прямые методы (метод исключения Гаусса, Гаусса-Жордана и прочие). Хорошо известно, что методы этого класса не эффективны при решении плохо обусловленных систем и систем высокой размерности. Как правило, в вычислительной практике применяют итерационные методы и, в частности, методы, основанные на предобуславливателях [10].
Известно значительное число методов предобуславливания: приближенные обратные методы; приближенные факторизованные обратные методы; методы, основанные на неполной треугольной факторизации и т. д. Методы различаются затратами на построение предобуславливателя, свойствами сходимости и масштабируемости при параллельной реализации.
В комплексе FlowVision используется алгоритм неполных треугольных факторизаций второго порядка точности ILU2, являющийся несимметричным обобщением алгоритма ICH2 [10]. Алгоритм ILU2 показал высокую вычислительную эффективность для широкого класса задач, в том числе, для задач вычислительной гидрогазодинамики [11]. Ставится задача реализации этого алгоритма на ГПУ.
2. Распараллеливание алгоритма ILU2
Процесс факторизации в соответствии с алгоритмом ILU2 основан на матричном соотношении
![]() ,
,
где A ‑ масштабированная матрица системы (1), L и U — нижняя и верхняя треугольные части элементов первого порядка точности, W и R – аналогичные части элементов второго порядка точности, E ‑ матрица ошибок.
В итерационной схеме алгоритма ILU2 итерации производятся с матрицей ![]() . Алгоритм требует хранения в памяти ЭВМ всех элементов матриц A, L, U, небольшой части элементов матриц W и R и включает в себя следующие операции [11]:
. Алгоритм требует хранения в памяти ЭВМ всех элементов матриц A, L, U, небольшой части элементов матриц W и R и включает в себя следующие операции [11]:
1) построение предобуславливателя (неполная факторизация матрицы),
2) умножение матрицы на вектор,
3) решение систем уравнений с верхней и нижней треугольными матрицами,
4) векторные операции.
Для обеспечения высокой эффективности реализации на ГПУ алгоритма ILU2 необходимо согласованное распараллеливание всех указанных операций. Рассмотрим первые три из них.
Построение предобуславливателя. В блочном виде рекуррентное выражение для операции треугольной факторизации имеет вид
 .
.
Здесь блоки ![]() имеет единичный размер; блоки
имеет единичный размер; блоки ![]() являются строками; блоки
являются строками; блоки ![]() ‑ столбцами;
‑ столбцами; ![]() ‑ квадратные матрицы. На каждой итерации необходимы следующие операции:
‑ квадратные матрицы. На каждой итерации необходимы следующие операции:
1) на основе уравнения ![]() вычислить значения компонентов строк
вычислить значения компонентов строк ![]() ;
;
2) из уравнений 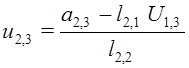 ,
, 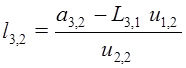 найти компоненты строки
найти компоненты строки ![]() и столбца
и столбца ![]() .
.
Зависимости по данным для строки матрицы ![]() представленного алгоритма иллюстрирует рисунок 1. Для столбца матрицы L зависимость по данным получается симметричным отражением представленных зависимостей относительно главной диагонали матрицы.
представленного алгоритма иллюстрирует рисунок 1. Для столбца матрицы L зависимость по данным получается симметричным отражением представленных зависимостей относительно главной диагонали матрицы.

Рисунок 1 ‑ Зависимости по данным при вычислении компонентов строки матрицы U в процессе факторизации
Различные варианты метода неполных разложений, в том числе алгоритмы ICH2, ILU2, представляют собой некоторые модификации шагов 1, 2 [11].
Умножение матрицы на вектор осуществляется по формуле [<анонимны2]
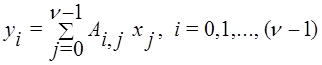 ,
,
из которой следует, что при выполнении данной операции рекуррентная зависимость по данным отсутствует.
Решение систем уравнений. Рекуррентные уравнения для решения треугольных систем с матрицами L и U имеют, соответственно, вид[<анонимны3]
 (2)
(2)
 (3)
(3)
Здесь ![]() ‑ элементы матриц
‑ элементы матриц ![]() .
.
Соответствующие зависимости по данным иллюстрирует рисунок 2.
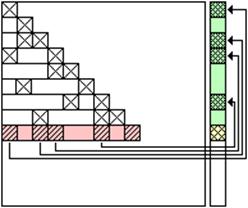

а) б)
Рисунок 2 ‑ Зависимости по данным: а) для рекуррентных уравнений (2); б) для рекуррентных уравнений (3)
Положим, что существует такая нумерация переменных, что матрица СЛАУ имеет вид
 (4)
(4)
где ![]() ‑ квадратные блоки. Будем говорить, что эта матрица является p-блочно-окаймленной.
‑ квадратные блоки. Будем говорить, что эта матрица является p-блочно-окаймленной.
Легко видеть, что p-блочно-окаймленное представление матрицы ![]() дает возможность организовать независимую параллельную факторизацию pдиагональных блоков
дает возможность организовать независимую параллельную факторизацию pдиагональных блоков ![]() . В то же время, факторизация окаймляющих блоков не может быть выполнена независимо.
. В то же время, факторизация окаймляющих блоков не может быть выполнена независимо.
Существуют различные способы нумерации переменных, при которых матрица СЛАУ приобретает вид (4). Например, в методе вложенных сечений[<анонимны4] [11] строится расщепление вида (4) при p=2. Для каждого из полученных блоков снова строится расщепление вида (4) при p=2 и так далее (рисунок 3).
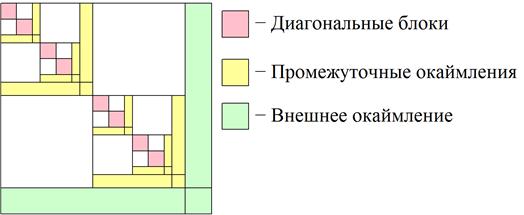
Рисунок 3. К методу вложенных сечений (четыре уровня расщепления)
Представление (4) можно получить на основе геометрической декомпозиции исходной краевой задачи для ДУЧП, когда расчетная область задачи разбивается на несколько подобластей, каждая из которых связна и имеет минимальную из возможных границу с другими подобластями [11]. На основе такой декомпозиции можно организовать двухуровневое распараллеливание при решении задачи на мультикомпьютере, узлами которого являются мультипроцессоры или многоядерные процессоры, по следующей схеме: на верхнем уровне иерархии каждую из подобластей ставим в соответствие одному узлу вычислительной системы; на втором уровне иерархии распараллеливание в пределах подобласти осуществляем, используя многопроцессорность или многоядерность узла.
Для ГПУ рассмотренная схема распараллеливания не может обеспечить высокую эффективность вычислений, поскольку позволяет реализовать параллелизм уровня мультипроцессоров (cuda-блоков), но не позволяет использовать параллелизм уровня потоковых процессоров (cuda-потоков). С целью обеспечения высокой эффективности параллельных вычислений на ГПУ используем так называемое мелкоблочное (м-блочное) представление разреженной матрицы.
Мелкоблочная разреженная матрица ![]() появляется при моделировании сложных физических процессов, имеющих место, в частности, в задачах гидрогазодинамики. Такие задачи требуют учета взаимовлияния различных физических величин, например, скорости, давления, температуры, плотности и т. д. Указанные величины можно пронумеровать таким образом, чтобы неизвестные, соответствующие одному узлу расчетной сетки, оказались в векторе неизвестных
появляется при моделировании сложных физических процессов, имеющих место, в частности, в задачах гидрогазодинамики. Такие задачи требуют учета взаимовлияния различных физических величин, например, скорости, давления, температуры, плотности и т. д. Указанные величины можно пронумеровать таким образом, чтобы неизвестные, соответствующие одному узлу расчетной сетки, оказались в векторе неизвестных ![]() рядом, а коэффициенты при них образовали плотные м-блоки в структуре матрицы
рядом, а коэффициенты при них образовали плотные м-блоки в структуре матрицы ![]() . В трехмерном случае для задачи гидродинамики без учета теплообмена м-блоки имеют размерность
. В трехмерном случае для задачи гидродинамики без учета теплообмена м-блоки имеют размерность ![]() (три декартовых компоненты скорости и давление), в той же задаче, но с учетом теплообмена, ‑ размерность
(три декартовых компоненты скорости и давление), в той же задаче, но с учетом теплообмена, ‑ размерность ![]() и т. д.
и т. д.
Исходим из предположения, что все м-блоки матрицы ![]() являются плотными и храним все компоненты каждого из этих блоков.
являются плотными и храним все компоненты каждого из этих блоков.
Недостаток м-блочного представления матрицы ![]() заключается в том, что случае наличия в м-блоке всего одного ненулевого элемента, требуется хранить весь этот блок. Достоинством м-блочного представления является возможность увеличения числа однотипных вычислительных операций, что позволяет обеспечить более полную загрузку ГПУ на уровне потоковых процессоров.
заключается в том, что случае наличия в м-блоке всего одного ненулевого элемента, требуется хранить весь этот блок. Достоинством м-блочного представления является возможность увеличения числа однотипных вычислительных операций, что позволяет обеспечить более полную загрузку ГПУ на уровне потоковых процессоров.
В работе выполнена реализация на ГПУ двух основных операций алгоритма ILU2: умножение м-блочной матрицы на набор векторов (операция, в которой отсутствуют зависимости по данным); решение м-блочно-треугольной СЛАУ (операция, имеющая зависимости по данным).
Рекуррентные соотношения при решении м-блочно-треугольной системы с матрицами L, U аналогичны уравнениям (2), (3) и имеют вид
 (5)
(5)
 (6)
(6)
Здесь ![]() ‑ число м-блочных строк в матрице
‑ число м-блочных строк в матрице ![]() ;
; ![]() ‑ м-блоки соответствующих матриц;
‑ м-блоки соответствующих матриц; ![]() ‑ м-подвекторы векторов
‑ м-подвекторы векторов ![]() соответственно.
соответственно.
Из выражений (5), (6) следует, что схема зависимостей по данным для м-блочно-треугольных систем аналогична схеме зависимостей обычной треугольной системы (рисунок 2) с той разницей, что вместо скалярных величин в этой схеме фигурируют м-блоки матриц и м-подвекторы переменных.
Алгоритм (5), (6), во-первых, имеет имеется крупноблочную структуру типа (4), позволяющую осуществить эффективное распараллеливание на уровне ядер ЦПУ либо на уровне мультипроцессоров ГПУ. Во-вторых, этот алгоритм включает в себя операции умножения плотного м-блока на плотный м-подвектор, что дает возможность реализовать распараллеливание вычислений на уровне потоковых процессоров ГПУ.
3. Программная реализация
Представление матриц. В программной реализации используем квадратные матрицы с квадратными м-блоками постоянного размера. Разреженную м-блочную матрицу представляем в виде, основанном на йельском формате, который также известен как формат CSR (CompressedSparseRow).
Формат предусматривает использование массивов A, I, J. Здесь массив A имеет размерность ![]() , где m ‑ число м-блоков в матрице, а n ‑ размер блока. Элементы исходной матрицы сгруппированы в массиве Aпо блокам, а внутри блока ‑ по строкам (рисунок 4).
, где m ‑ число м-блоков в матрице, а n ‑ размер блока. Элементы исходной матрицы сгруппированы в массиве Aпо блокам, а внутри блока ‑ по строкам (рисунок 4).
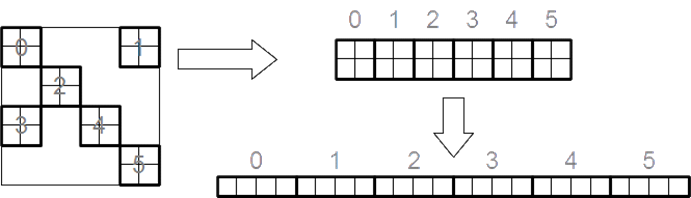
Рисунок 4 ‑ Преобразование м-блочной матрицы в линейный массив А
Массив J имеет размерность m и в своем j-м элементе содержит номер м-блочного столбца элементов, записанных в позициях ![]() массива A. Массив I имеет размерность N+1. В i-й позиции массив содержит индекс, с которого в массиве J начинаются элементы, соответствующие i-й м-блочной строке матрицы. В последней N-й позиции массив содержит размерность вектора J (рисунок 5).
массива A. Массив I имеет размерность N+1. В i-й позиции массив содержит индекс, с которого в массиве J начинаются элементы, соответствующие i-й м-блочной строке матрицы. В последней N-й позиции массив содержит размерность вектора J (рисунок 5).
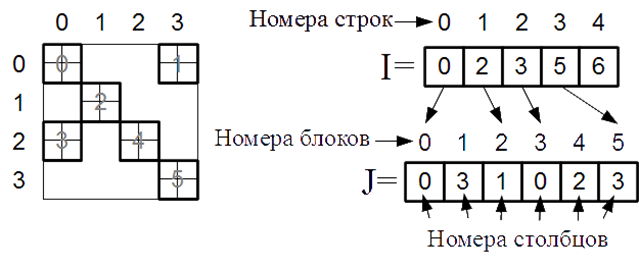
Рисунок 5 ‑ Вспомогательные индексные массивы
Представление набора векторов. Набор из k плотных векторов размерности ν=Nn естественно представить в виде k массивов размерности ν или одного массива размерности ![]() , в котором векторы расположены один за другим (рисунок 6). Однако такое представление приводит к большому числу нелокальных обращений к памяти процессора и, как следствие, к снижению производительности. Поэтому используем построчное хранение векторов. В данном формате векторы хранятся в массиве размерностью
, в котором векторы расположены один за другим (рисунок 6). Однако такое представление приводит к большому числу нелокальных обращений к памяти процессора и, как следствие, к снижению производительности. Поэтому используем построчное хранение векторов. В данном формате векторы хранятся в массиве размерностью ![]() в следующем порядке: первый элемент первого вектора; первый элемент второго вектора; … первый элемент k-го вектора; второй элемент первого вектора и т. д. (рисунок 7).
в следующем порядке: первый элемент первого вектора; первый элемент второго вектора; … первый элемент k-го вектора; второй элемент первого вектора и т. д. (рисунок 7).

Рисунок 6 – «Естественный» формат хранения набора векторов

Рисунок 7 ‑ Формат, обеспечивающий локальность обращений к памяти
3.1. Умножение матрицы на набор векторов
В рамках реализации умножения матрицы на набор векторов были разработаны четыре параллельных CUDA-алгоритма (алгоритмы ![]() ‑
‑ ![]() ), аналогичный алгоритм
), аналогичный алгоритм ![]() последовательного умножения, а также алгоритм
последовательного умножения, а также алгоритм ![]() для измерения производительности параллельных вычислений.
для измерения производительности параллельных вычислений.
Алгоритм ![]() каждой м-блочной строке ставит в соответствие один CUDA-поток. В этом потоке последовательно производится умножение всех элементов м-блочной строки на соответствующие элементы набора векторов. Параллелизм достигается за счет большого числа м-блочных строк. CUDA-потоки группируются в CUDA-блоки по 1024 потока в каждом (рисунок 8). Требуемое число CUDA-блоков определяется автоматически.
каждой м-блочной строке ставит в соответствие один CUDA-поток. В этом потоке последовательно производится умножение всех элементов м-блочной строки на соответствующие элементы набора векторов. Параллелизм достигается за счет большого числа м-блочных строк. CUDA-потоки группируются в CUDA-блоки по 1024 потока в каждом (рисунок 8). Требуемое число CUDA-блоков определяется автоматически.
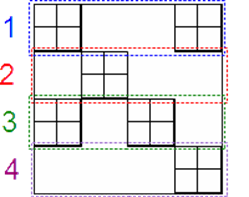
Рисунок 8 ‑ Распределение м-блоков матрицы СЛАУ по CUDA-потокам: алгоритм ![]()
Алгоритм ![]() не использует разделяемую память ГПУ, наиболее прост в реализации, обеспечивает отсутствие конфликтов при записи результатов вычислений в память. С другой стороны, алгоритм не может гарантировать высокую эффективностью из-за большого числа нелокальных несогласованных обращений к памяти из одной рабочей группы (warp). При малых размерностях матрицы СЛАУ алгоритм не обеспечивает сбалансированную загрузку ГПУ.
не использует разделяемую память ГПУ, наиболее прост в реализации, обеспечивает отсутствие конфликтов при записи результатов вычислений в память. С другой стороны, алгоритм не может гарантировать высокую эффективностью из-за большого числа нелокальных несогласованных обращений к памяти из одной рабочей группы (warp). При малых размерностях матрицы СЛАУ алгоритм не обеспечивает сбалансированную загрузку ГПУ.
Алгоритм ![]() . В данном алгоритме каждой м-блочной строке ставим в соответствие один CUDA-блок, а каждой комбинации «строка м-блока – м-подвектор» ‑ один CUDA-поток (рисунок 9). Таким образом, для умножения
. В данном алгоритме каждой м-блочной строке ставим в соответствие один CUDA-блок, а каждой комбинации «строка м-блока – м-подвектор» ‑ один CUDA-поток (рисунок 9). Таким образом, для умножения ![]() м-блока на k м-подвекторов требуется nk CUDA-потоков. Умножение производим параллельно, так что в результате получается
м-блока на k м-подвекторов требуется nk CUDA-потоков. Умножение производим параллельно, так что в результате получается ![]() блоков размерности
блоков размерности ![]() каждый, где
каждый, где ![]() ‑ число м-блоков в одной блочной строке матрицы СЛАУ, и алгоритм требует для работы
‑ число м-блоков в одной блочной строке матрицы СЛАУ, и алгоритм требует для работы ![]() CUDA-потоков. Перед умножением м-блоки загружаем в разделяемую память ГПУ для уменьшения задержек. После умножения элементы всех м-блоков суммируем с использованием атомарных операций (для обеспечения отсутствия конфликтов по записи).
CUDA-потоков. Перед умножением м-блоки загружаем в разделяемую память ГПУ для уменьшения задержек. После умножения элементы всех м-блоков суммируем с использованием атомарных операций (для обеспечения отсутствия конфликтов по записи).
Алгоритм ![]() также достаточно прост в реализации, значительно лучше алгоритма
также достаточно прост в реализации, значительно лучше алгоритма ![]() обеспечивает согласованность обращений к памяти и лучшую балансировку загрузки. Однако, в случае
обеспечивает согласованность обращений к памяти и лучшую балансировку загрузки. Однако, в случае ![]() , где
, где ![]() - число CUDA-потоков в CUDA-блоке, алгоритм дает неверный результат. Данная ситуация имеет место, например, при размерности блока
- число CUDA-потоков в CUDA-блоке, алгоритм дает неверный результат. Данная ситуация имеет место, например, при размерности блока ![]() , числе векторов
, числе векторов ![]() и числе м-блоков в блочной строке
и числе м-блоков в блочной строке ![]() . Это связано с тем, что в данном алгоритме не предусмотрена организация цикла при превышении числом потоков величины
. Это связано с тем, что в данном алгоритме не предусмотрена организация цикла при превышении числом потоков величины ![]() . Для оборудования, использовавшегося в ходе выполнения данной работы,
. Для оборудования, использовавшегося в ходе выполнения данной работы, ![]() .
.
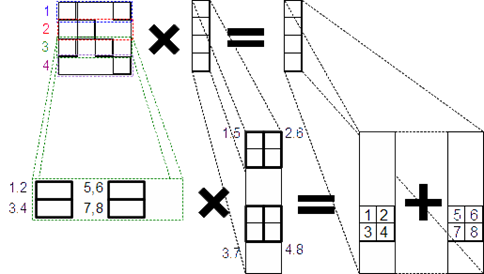
Рисунок 9 ‑ Распределение м-блоков матрицы по CUDA-блокам, а также строк м-блоков матрицы и наборов векторов по CUDA-потокам: алгоритм ![]()
Алгоритм ![]() идентичен алгоритму
идентичен алгоритму ![]() за исключением того, что в случае превышения величиной
за исключением того, что в случае превышения величиной ![]() значения
значения ![]() , он реализует вычисления в несколько итераций до тех пор, пока не будут обработаны все м-блоки строки.
, он реализует вычисления в несколько итераций до тех пор, пока не будут обработаны все м-блоки строки.
Алгоритм ![]() . В данном алгоритме одному CUDA-блоку ставим в соответствие фиксированное число м-блочных строк матрицы. Это позволяет избежать ситуации, когда на один CUDA-блок приходится всего один – три м-блока матрицы, так что имеет место простой большого числа потоковых процессоров (рисунок 10). Таким образом, алгоритм
. В данном алгоритме одному CUDA-блоку ставим в соответствие фиксированное число м-блочных строк матрицы. Это позволяет избежать ситуации, когда на один CUDA-блок приходится всего один – три м-блока матрицы, так что имеет место простой большого числа потоковых процессоров (рисунок 10). Таким образом, алгоритм ![]() обеспечивает более равномерную загрузку ГПУ в случае, если в матрице присутствуют м-строки с малым числом блоков.
обеспечивает более равномерную загрузку ГПУ в случае, если в матрице присутствуют м-строки с малым числом блоков.
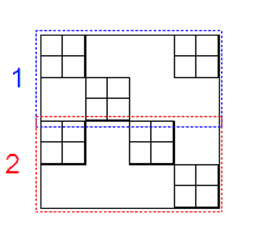
Рисунок 10 ‑ Распределение м-блоков матрицы по CUDA-блокам:
алгоритм ![]()
Алгоритм ![]() представляет собой, по сути, классический последовательный алгоритм умножения блочно-разреженной матрицы размерности
представляет собой, по сути, классический последовательный алгоритм умножения блочно-разреженной матрицы размерности ![]() на плотную матрицу размерности
на плотную матрицу размерности ![]() .
.
Алгоритм ![]() реализует следующие операции: умножение матрицы на вектор последовательным алгоритмом; определение времени исполнение алгоритма; умножение матрицы на вектор исследуемым параллельным алгоритмом; измерение времени исполнения алгоритма; вычисление ускорения параллельного алгоритма.
реализует следующие операции: умножение матрицы на вектор последовательным алгоритмом; определение времени исполнение алгоритма; умножение матрицы на вектор исследуемым параллельным алгоритмом; измерение времени исполнения алгоритма; вычисление ускорения параллельного алгоритма.
3.2. Решение блочно-треугольной СЛАУ
Для решения данной задачи также разработаны четыре параллельных CUDA-алгоритма (алгоритмы ![]() ), аналогичный последовательный алгоритм
), аналогичный последовательный алгоритм ![]() , а также алгоритм
, а также алгоритм ![]() для измерения производительности параллельных вычислений
для измерения производительности параллельных вычислений
Алгоритм ![]() реализует только те возможности распараллеливания, которые дает структура матрицы СЛАУ вида (4). Для матриц U и L, полученных при факторизации матрицы A, построенной в соответствии с методом вложенных сечений, алгоритм строит бинарное дерево, корень которого соответствует внешнему окаймлению, листья соответствуют блокам
реализует только те возможности распараллеливания, которые дает структура матрицы СЛАУ вида (4). Для матриц U и L, полученных при факторизации матрицы A, построенной в соответствии с методом вложенных сечений, алгоритм строит бинарное дерево, корень которого соответствует внешнему окаймлению, листья соответствуют блокам ![]() , а промежуточные вершины ‑ промежуточным окаймлениям (рисунок 3). Вычисление неизвестных, соответствующих вершинам, лежащим на одном уровне дерева, производится параллельно. При этом существует зависимость неизвестных i-го уровня от неизвестных (i+1)-го уровня для системы с
, а промежуточные вершины ‑ промежуточным окаймлениям (рисунок 3). Вычисление неизвестных, соответствующих вершинам, лежащим на одном уровне дерева, производится параллельно. При этом существует зависимость неизвестных i-го уровня от неизвестных (i+1)-го уровня для системы с ![]() матрицей и от неизвестных (
матрицей и от неизвестных (![]() )-го уровня ‑ для системы с Lматрицей.
)-го уровня ‑ для системы с Lматрицей.
Каждому набору неизвестных, соответствующих какой-либо вершине дерева, назначаем одно CUDA-ядро, внутри которого вычисления организованы последовательно. Таким образом, одновременно выполняется число потоков, не большее числа потоковых мультипроцессоров используемого ГПУ.
Параллельные алгоритмы ![]() ‑
‑ ![]() построены на основе данного алгоритма.
построены на основе данного алгоритма.
Алгоритм ![]() реализует распараллеливание на уровне м-блока. Матрично-векторные операции с м-блоками выполняем параллельно nCUDA-потоками в составе CUDA-ядра.
реализует распараллеливание на уровне м-блока. Матрично-векторные операции с м-блоками выполняем параллельно nCUDA-потоками в составе CUDA-ядра.
Алгоритм ![]() использует распараллеливание циклов. На каждой итерации, обрабатывающей одну м-блочную строку матрицы СЛАУ, выполняем параллельные независимые умножения м-блоков на м-подвектор переменных. Каждому м-блоку ставим в соответствие один CUDA-поток. Поскольку в разных м-строках число блоков различно, при запуске вычислений CUDA-ядру назначаем максимально возможное число CUDA-потоков. При превышении этим числом числа м-блоков в строке лишние потоки отсекаем, а в противном случае организуем циклическую обработку м-блоков в строке.
использует распараллеливание циклов. На каждой итерации, обрабатывающей одну м-блочную строку матрицы СЛАУ, выполняем параллельные независимые умножения м-блоков на м-подвектор переменных. Каждому м-блоку ставим в соответствие один CUDA-поток. Поскольку в разных м-строках число блоков различно, при запуске вычислений CUDA-ядру назначаем максимально возможное число CUDA-потоков. При превышении этим числом числа м-блоков в строке лишние потоки отсекаем, а в противном случае организуем циклическую обработку м-блоков в строке.
Алгоритм ![]() представляет собой комбинацию алгоритмов
представляет собой комбинацию алгоритмов ![]() ,
, ![]() . В каждом CUDA-ядре в этом случае выделяем
. В каждом CUDA-ядре в этом случае выделяем ![]() CUDA-потоков. Параллельно выполняем матрично-векторные операции с независимыми м-блоками в одной м-строке, а каждую из этих операций дополнительно распараллеливаем по строкам м-блока.
CUDA-потоков. Параллельно выполняем матрично-векторные операции с независимыми м-блоками в одной м-строке, а каждую из этих операций дополнительно распараллеливаем по строкам м-блока.
Алгоритм ![]() реализует поиск неизвестных в соответствии с формулами (5), (6), то есть, по сути, представляет собой м-блочный вариант обратного хода метода исключения Гаусса.
реализует поиск неизвестных в соответствии с формулами (5), (6), то есть, по сути, представляет собой м-блочный вариант обратного хода метода исключения Гаусса.
Алгоритм ![]() аналогичен алгоритму
аналогичен алгоритму ![]() .
.
4. Тестирование и исследование эффективности алгоритмических и программных решений
Для проверки корректности принятых алгоритмических и программных решений использованы СЛАУ с известными точными решениями. Результаты тестирования показали погрешность порядка ![]() при использовании чисел с плавающей запятой двойной точности и погрешность порядка
при использовании чисел с плавающей запятой двойной точности и погрешность порядка ![]() при использовании таких же чисел одинарной точности. Порядок системы варьировался от
при использовании таких же чисел одинарной точности. Порядок системы варьировался от ![]() до
до ![]() .
.
Вычислительные эксперименты выполнены на ПЭВМ с центральным процессором Intel Core 2 Duo E8600 с 2 ГБ ОЗУ и ГПУ NVIDIA GeForce GTX 460SE с 1 ГБ памяти. При определении ускорения ![]() параллельных алгоритмов в качестве времени исполнения последовательного алгоритма использовано время решения соответствующей задачи на одном ядре ЦПУ. В качестве времени исполнения параллельного алгоритма использовано а) «чистое» время исполнения CUDA-ядра, б) время выполнения вместе с временем предварительного копирования матрицы в память ГПУ. Соответственно, для каждого из исследуемых параллельных алгоритмов были получены по два значения ускорения. При использовании этих алгоритмов в программном комплексе FlowVision предполагается, что на одну операцию копирования матрицы приходится несколько десятков умножений матрицы на набор векторов или решений СЛАУ и что новые векторы для очередной операции будут копироваться в память ГПУ параллельно с вычислениями. Поэтому далее представляем только ускорения, соответствующие варианту (а) исполнения параллельных алгоритмов.
параллельных алгоритмов в качестве времени исполнения последовательного алгоритма использовано время решения соответствующей задачи на одном ядре ЦПУ. В качестве времени исполнения параллельного алгоритма использовано а) «чистое» время исполнения CUDA-ядра, б) время выполнения вместе с временем предварительного копирования матрицы в память ГПУ. Соответственно, для каждого из исследуемых параллельных алгоритмов были получены по два значения ускорения. При использовании этих алгоритмов в программном комплексе FlowVision предполагается, что на одну операцию копирования матрицы приходится несколько десятков умножений матрицы на набор векторов или решений СЛАУ и что новые векторы для очередной операции будут копироваться в память ГПУ параллельно с вычислениями. Поэтому далее представляем только ускорения, соответствующие варианту (а) исполнения параллельных алгоритмов.
Поскольку в вычислительных экспериментах в качестве host-ЭВМ использована ПЭВМ, функционирующая в мультипрограммном режиме, время исполнения последовательных алгоритмов оказывается случайной величиной. В результате этого случайными оказываются и ускорения параллельных алгоритмов. На рисунке 11 в качестве примера показаны графики ускорений, полученных при одинаковых параметрах задачи в двух запусках одной из параллельных программ умножения матрицы на набор векторов.

Рисунок 11 – К эффекту случайных флуктуаций ускорения
Для минимизации влияния случайных флуктуаций времени выполнения последовательной программы на ускорение каждый из вычислительных экспериментов проводился многократно, выбросы ускорения игнорировались, а оставшиеся значения усреднялись (рисунок 12).
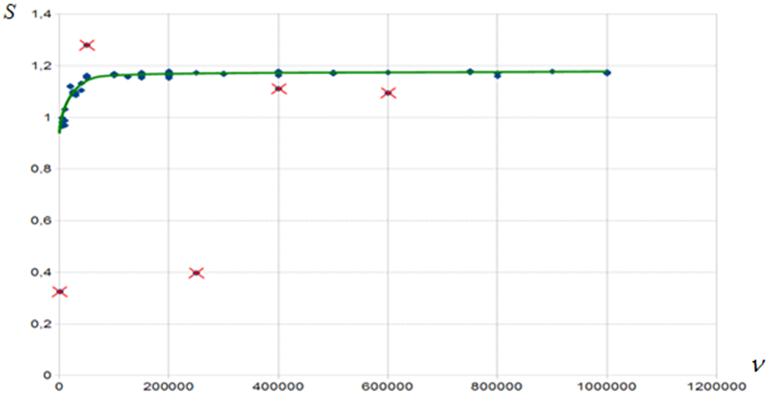
Рисунок 12 – К методике борьбы со случайными флуктуациями ускорения
4.1. Алгоритмы умножения матрицы на набор векторов
Алгоритм ![]() . Результаты исследования эффективности данного алгоритма иллюстрирует рисунок 13. Из рисунка следует, что алгоритм
. Результаты исследования эффективности данного алгоритма иллюстрирует рисунок 13. Из рисунка следует, что алгоритм ![]() в сравнении с алгоритмом
в сравнении с алгоритмом ![]() обеспечивает небольшой выигрыш во времени решения задачи, который уменьшается с увеличением размера м-блока. Такой результат объясняется тем, что алгоритм
обеспечивает небольшой выигрыш во времени решения задачи, который уменьшается с увеличением размера м-блока. Такой результат объясняется тем, что алгоритм ![]() противоречит концепции SIMD-вычислений, поскольку в данном случае в разных CUDA-потоках одного CUDA-блока приходится выполнять разные последовательности вычислений.
противоречит концепции SIMD-вычислений, поскольку в данном случае в разных CUDA-потоках одного CUDA-блока приходится выполнять разные последовательности вычислений.

Рисунок 13 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
Алгоритмы ![]() ,
, ![]() . Данные алгоритмы имеют близкую структуру и для них были получены близкие результаты. Поэтому эти алгоритмы рассматриваем вместе.
. Данные алгоритмы имеют близкую структуру и для них были получены близкие результаты. Поэтому эти алгоритмы рассматриваем вместе.
На рисунках 14, 15 представлены зависимости ускорения от числа м-блоков матрицы СЛАУ для пяти и девяти векторов соответственно. Рисунки показывают, что алгоритмы ![]() ,
, ![]() обеспечивают значительно более высокую эффективность по сравнению с алгоритмом
обеспечивают значительно более высокую эффективность по сравнению с алгоритмом ![]() . Так, при девяти векторах и размерности м-блока, равной
. Так, при девяти векторах и размерности м-блока, равной ![]() , ускорения достигает величины ~17 (рисунок 15). В то же время, лишь двукратное ускорение при м-блоках размерности
, ускорения достигает величины ~17 (рисунок 15). В то же время, лишь двукратное ускорение при м-блоках размерности ![]() и повышение ускорения в 7,5 раз при увеличении размерности м-блоков в три раза до
и повышение ускорения в 7,5 раз при увеличении размерности м-блоков в три раза до ![]() , говорит о недостаточной загрузке ГПУ при малых размерах м-блоков.
, говорит о недостаточной загрузке ГПУ при малых размерах м-блоков.
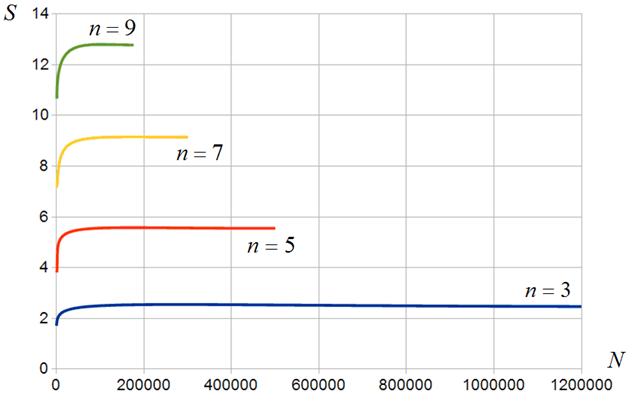
Рисунок 14 ‑ Ускорение вычислений в функции числа м-блоков: алгоритмы ![]() ,
, ![]() ;
; ![]()
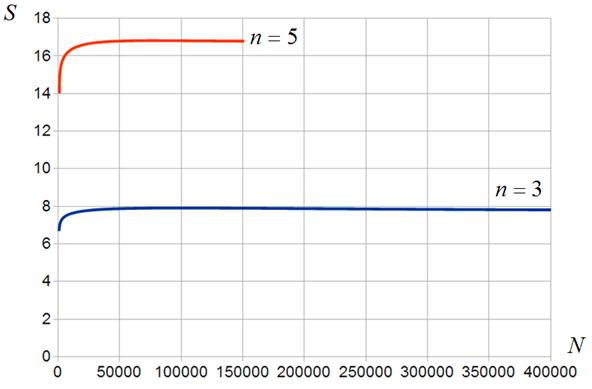
Рисунок 15 ‑ Ускорение вычислений в функции числа м-блоков: алгоритмы ![]() ,
, ![]() ;
; ![]()
Алгоритм ![]() . Результаты исследования эффективности данного алгоритма представлены на рисунках 16, 17. Рисунки показывают, что по сравнению с алгоритмами
. Результаты исследования эффективности данного алгоритма представлены на рисунках 16, 17. Рисунки показывают, что по сравнению с алгоритмами ![]() ,
, ![]() , алгоритм
, алгоритм ![]() обеспечивает рост минимального ускорения примерно в три раза и некоторое падение максимального ускорения. Эффект объясняется тем, что, с одной стороны, при малом размере м-блоков работа с несколькими его строками в одном CUDA-блоке позволяет улучшить балансировку загрузки ГПУ. С другой стороны, при большом размере м-блоков существенными оказываются дополнительные затраты на организацию цикла по строкам.
обеспечивает рост минимального ускорения примерно в три раза и некоторое падение максимального ускорения. Эффект объясняется тем, что, с одной стороны, при малом размере м-блоков работа с несколькими его строками в одном CUDA-блоке позволяет улучшить балансировку загрузки ГПУ. С другой стороны, при большом размере м-блоков существенными оказываются дополнительные затраты на организацию цикла по строкам.
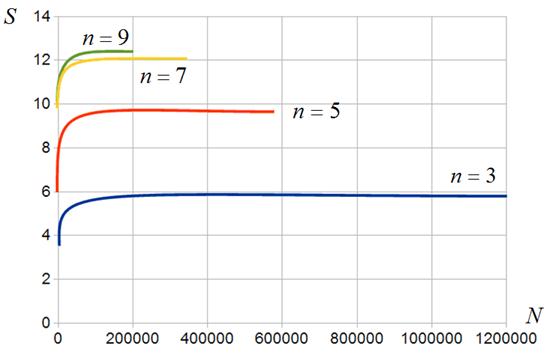
Рисунок 16 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
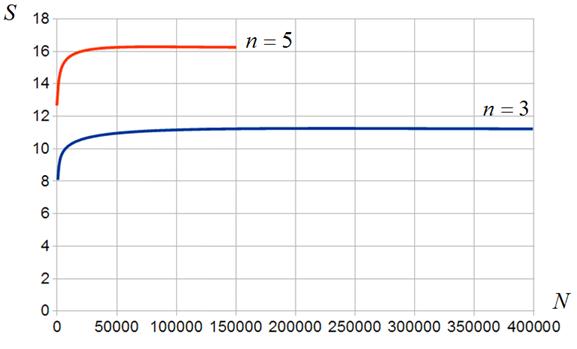
Рисунок 17 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
4.2. Алгоритмы решения блочно-треугольной СЛАУ
Результаты исследования эффективности алгоритма ![]() не приводим, поскольку данный алгоритм проектировался лишь как основа для построения алгоритмов
не приводим, поскольку данный алгоритм проектировался лишь как основа для построения алгоритмов ![]() .
.
Алгоритм ![]() . Некоторые результаты исследования эффективности алгоритма для высоты дерева h, равной четырем и шести, представлены на рисунках 18, 19 соответственно. Рисунок 18 показывает, что в первом случае алгоритм обеспечивает замедление вычислений по сравнению с ЦПУ. Этот факт объясняется малой максимальной шириной дерева, составляющей в данном случае всего восемь узлов. В результате мультипроцессоры ГПУ оказываются загруженными далеко не полностью. Во втором случае, когда высота дерева равна шести, его максимальная ширина составляет 32 узла. Это позволяет загрузить ГПУ более полно и обеспечить меньшее падение его производительности (рисунок 19). Представленные далее результаты исследования эффективности алгоритмов
. Некоторые результаты исследования эффективности алгоритма для высоты дерева h, равной четырем и шести, представлены на рисунках 18, 19 соответственно. Рисунок 18 показывает, что в первом случае алгоритм обеспечивает замедление вычислений по сравнению с ЦПУ. Этот факт объясняется малой максимальной шириной дерева, составляющей в данном случае всего восемь узлов. В результате мультипроцессоры ГПУ оказываются загруженными далеко не полностью. Во втором случае, когда высота дерева равна шести, его максимальная ширина составляет 32 узла. Это позволяет загрузить ГПУ более полно и обеспечить меньшее падение его производительности (рисунок 19). Представленные далее результаты исследования эффективности алгоритмов ![]() относятся только к высоте дерева
относятся только к высоте дерева ![]() .
.
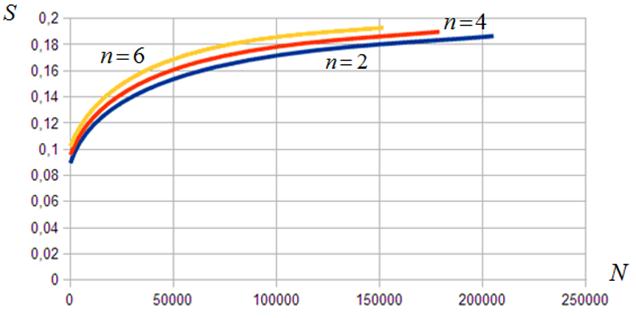
Рисунок 18 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()

Рисунок 19 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
Алгоритм ![]() . Сравнение результатов, представленных на рисунках 19, 20, показывает, что распараллеливание цикла и распараллеливание матрично-векторных операций дают почти одинаково неудовлетворительные результаты – время решения СЛАУ на ГПУ оказывается более чем в два раза выше того же времени при использовании только ЦПУ.
. Сравнение результатов, представленных на рисунках 19, 20, показывает, что распараллеливание цикла и распараллеливание матрично-векторных операций дают почти одинаково неудовлетворительные результаты – время решения СЛАУ на ГПУ оказывается более чем в два раза выше того же времени при использовании только ЦПУ.

Рисунок 20 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
Алгоритм ![]() . Результаты исследования эффективности данного алгоритма представлены на рисунке 21, из которого следует, что этот алгоритм обеспечивает наиболее высокую из числа рассмотренных алгоритмов производительность. Рисунок показывает быстрый рост ускорения с ростом размера м-блоков – если при блоках размером
. Результаты исследования эффективности данного алгоритма представлены на рисунке 21, из которого следует, что этот алгоритм обеспечивает наиболее высокую из числа рассмотренных алгоритмов производительность. Рисунок показывает быстрый рост ускорения с ростом размера м-блоков – если при блоках размером ![]() ускорение лишь немногим превышает единицу, то для
ускорение лишь немногим превышает единицу, то для ![]() -блоков оно становится почти двукратным. Таким образом, хотя для реальных задач требуется более высокая производительность, достигнутый результат можно считать удовлетворительным, поскольку в таких задачах, как правило, используются СЛАУ более высокой размерности, размеры м-блоков могут превышать указанные, объем памяти профессиональных ГПУ выше.
-блоков оно становится почти двукратным. Таким образом, хотя для реальных задач требуется более высокая производительность, достигнутый результат можно считать удовлетворительным, поскольку в таких задачах, как правило, используются СЛАУ более высокой размерности, размеры м-блоков могут превышать указанные, объем памяти профессиональных ГПУ выше.
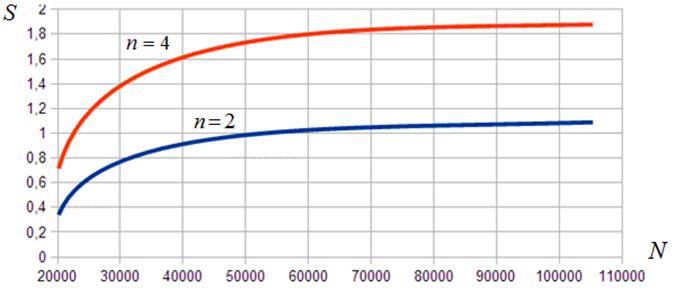
Рисунок 21 ‑ Ускорение вычислений в функции числа м-блоков: алгоритм ![]() ;
; ![]()
Заключение
Разработаны параллельные алгоритмы для ГПУ, реализующие основные операции алгоритма решения СЛАУ с предобуславливанием – операция умножения матрицы на набор векторов и операция решения блочно-треугольной СЛАУ. Разработано CUDA-программное обеспечение, реализующее указанные алгоритмы. Выполнено широкое исследование эффективности предложенных алгоритмических и программных решений.
Исследование показало достаточно высокую эффективность разработанных алгоритмов и программ для умножения матрицы на набор векторов ‑ достигнуто ускорение от четырех до шестнадцати раз (в зависимости от числа и размера м-блоков). Результаты исследования позволяют рекомендовать наиболее эффективный из рассмотренных алгоритмов и его программную реализацию к внедрению в промышленную версию комплекса FlowVision.
Разработанные алгоритмы и программы, предназначенные для решения блочно-треугольной СЛАУ, показали удовлетворительные результаты, которые позволяют ожидать приемлемого ускорения для практически значимых СЛАУ высокой размерности и при использовании профессиональных ГПУ. Для принятия окончательного решения о внедрении данных алгоритмов и соответствующих программ в комплекс FlowVision требуются дополнительные исследования.
В развитие работы авторы планируют разработку и исследование эффективности параллельных алгоритмов и программ, предназначенных для выполнения операций неполной факторизации матрицы и векторных операций. Результаты данной работы позволяют надеяться, что производительность векторных операций, в которых отсутствуют зависимости по данным, будет сопоставима с производительностью умножения матрицы на набор векторов, а производительности операций неполной факторизации, в которой такие зависимости присутствуют – с производительностью решения блочно-треугольной СЛАУ.
Список литературы
1. FlowVision. Режим доступа: http://www.flowvision.ru/)/ (дата обращения 28.12.2012).
2. Трудоншин В.А., Пивоваров Н.В. Системы автоматизированного проектирования. В 9 кн. Кн. 4. Математические модели технических объектов: учеб. пособие для втузов / Под ред. И.П. Норенкова. М.: Высшая школа, 1986. 160 с.
3. Смирнов Е.М., Зайцев Д.К. Метод конечных объемов в приложении к задачам гидрогазодинамики и теплообмена в областях сложной геометрии // Научно-технические ведомости СПбГПУ. 2004. № 2 (36). С. 70-81.
4. Адинец А., Воеводин В. Графический вызов суперкомпьютерам // Открытые системы. 2008. № 4. Режим доступа: http://www.osp.ru/os/2008/04/5114497/ (дата обращения 28.12.2012).
5. OpenCL. Режим доступа: http://opencl.ru/ (дата обращения 28.12.2012).
6. NVIDEA. Режим доступа: http://www.nvidia.ru/object/cuda_home_new_ru.html (дата обращения 28.12.2012).
7. CUBLAS. Режим доступа: http://docs.nvidia.com/cuda/cublas/index.html (дата обращения 28.12.2012).
8. CUSPARSE. Режим доступа: http://docs.nvidia.com/cuda/cusparse/index.html (дата обращения 28.12.2012).
9. Дядькин А.А., Харченко С.А. Алгоритмы декомпозиции области и нумерации ячеек с учетом локальных адаптаций расчетной сетки при параллельном решении систем уравнений в пакете FlowVision // Материалы Всероссийской научной конференции «Научный сервис в сети ИНТЕРНЕТ» (Новороссийск, 24-29 сентября 2007 г.). М.: Изд-воМосковскогоУниверситета, 2007. С. 201-206.
10. Kaporin I.E. High Quality Preconditioning of a General Symmetric Positive Definite Matrix Based on its UTU+UTR+RTU decomposition // Numer. LinearAlgebraAppl. 1998. Vol. 5. P. 483-509.
11. Сушко Г.Б., Харченко С.А. Многопоточная параллельная реализация итерационного алгоритма решения систем линейных уравнений с динамическим распределением нагрузки по нитям вычислений // Параллельные вычислительные технологии (ПаВТ'2008): труды международной научной конференции (Санкт-Петербург, 28 января - 1 февраля 2008 г.). Челябинск: Изд. ЮУрГУ, 2008. С. 452-457. Режим доступа: http://omega.sp.susu.ac.ru/books/conference/PaVT2008/papers/Short_Papers/035.pdf (дата обращения 28.12.2012).
Публикации с ключевыми словами: CUDA, система линейных алгебраических уравнений, предобуславливание, графические процессорные устройства
Публикации со словами: CUDA, система линейных алгебраических уравнений, предобуславливание, графические процессорные устройства
Смотри также:
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||