научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
#11 ноябрь 2004
А.Ф. Гареев
Применение вероятностной нейронной сети для задачи классификации текстов
Показана возможность применения аппарата вероятностных нейронных сетей для классификации текстов. Приводятся практические результаты применения данного аппарата для классификации сообщений средств массовой информации.
1. Постановка задачи
Пусть имеется некоторое количество примеров текстов, каждый из которых
принадлежит одному из К заранее известных классов (рубрик). Требуется
создать алгоритм, который, будучи обученным на текстах-примерах, получая на
входе новый неизвестный текст, выдавал бы на выходе вектор (p1,…, pk)
где pi- вероятность того, что данный
текст принадлежит классу ![]() .
.
Задача классификации текстов сама по себе не нова. Известно множество попыток ее решения (например, см. [1]). Несмотря на различие подходов, практически все авторы приходили к необходимости использования для ее решения некоторого математического аппарата. Но для того, чтобы получить возможность использовать математический аппарат, необходимо разработать модель, которая позволила бы описывать тексты в терминах некоторых количественных характеристик. Суть одной из таких моделей состоит в том, что текст сообщения представляется в виде вектора в многомерном пространстве.

Рис. 1.
2. Векторное представление текста
Преобразование текста в вектор. Пусть имеется (d1,…, dN)
- словарь дескрипторов, где di -
слово-дескриптор, ![]() (в данной статье под дескриптором
понимается ключевое слово, приведенное к канонической форме). Этот словарь
задает базис n-мерного пространства, где n равно мощности словаря N.
(в данной статье под дескриптором
понимается ключевое слово, приведенное к канонической форме). Этот словарь
задает базис n-мерного пространства, где n равно мощности словаря N.
Исходный текст сообщения подвергается процедуре морфологического анализа с целью приведения всех слов, встречающихся в тексте, к канонической форме. Текст рассматривается как неупорядоченное множество лексических единиц T. Тогда вектор, представляющий текст, будет выглядеть следующим образом:
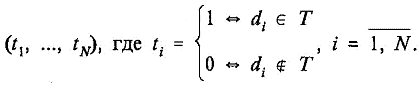
Можно усложнить модель, положив ti равным частоте встречаемости i-го дескриптора в данном тексте. Однако, если мы имеем дело с достаточно короткими текстами, например с сообщениями средств массовой информации, то первый вариант вполне адекватен, так как большинство дескрипторов встречается в таких текстах 1-2 раза, и принадлежность текста к определенной рубрике характеризуется скорее фактом наличия данного дескриптора (а точнее, комбинации дескрипторов) в тексте, нежели частотой его встречаемости.
Формирование словаря дескрипторов. Вообще говоря, формирование словаря дескрипторов является отдельной задачей. Например, словарь может формироваться экспертом, исходя из его знаний о предметной области. Однако существует возможность автоматизированного формирования словаря дескрипторов.
Словарь формируется на основе текстов примеров. Исходные тексты примеров подвергаются процедуре морфологического анализа с целью приведения всех слов, встречающихся в текстах, к канонической форме. Затем формируется непосредственно словарь дескрипторов. Первоначально в словарь включаются все слова, встречающиеся в текстах примеров. Дальнейшую обработку словаря можно разделить на два этапа.
1. Автоматическое усечение словаря за счет слов с низкой разрешающей способностью.
Изначально полученный словарь обычно имеет большую размерность. Однако большинство слов, входящих в него, имеют низкую частоту встречаемости (наибольшее количество слов встречается один раз).
Очевидно, что такие слова обладают низкой разрешающей способностью при классификации текстов. Слова с большой частотой встречаемости также имеют низкую разрешающую способность (обычно это союзы, предлоги и т.д.).
Таким образом, слова с частотой встречаемости выше верхней границы и ниже нижней границы можно отбросить (рис. 1). Кроме того, слова, встречающиеся с примерно одинаковой частотой во всех классах, бесполезны при классификации текстов и, следовательно, их тоже можно отбросить.
2. Редактирование словаря вручную.
В ходе ручного редактирования словаря из него исключаются слова, которые, по мнению оператора, несущественны при классификации.
Исходя из сказанного выше, полностью процесс формирования словаря дескрипторов можно представить в виде схемы, приведенной на рис. 2.
Теперь, представив текст в виде вектора, мы имеем возможность применить математические методы классификации.
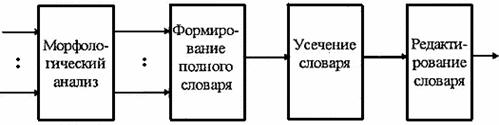
Рис. 2.
3. Классификация текстов
Выбор математического аппарата. В литературе упоминается множество математических методов, применявшихся для классификации текстов, как то: измерение евклидова расстояния, измерение косинуса угла между векторами. Применялся даже аппарат нечеткой логики (см. [1]).
В данной статье предлагается использовать аппарат нейронных сетей, которые являются классификаторами по своей природе. Предпочтение отдается именно вероятностным нейронным сетям, так как эта парадигма имеет:
строгое математическое обоснование (по сути вероятностная нейронная сеть представляет собой оптимальный по Байесу классификатор);
огромное (в тысячи раз большее) по сравнению с другими нейросетевыми парадигмами быстродействие (см. [2]).
Определение структуры сети для решения задачи классификации текстов и ее обучение. Количество нейронов во входном слое равно размерности словаря дескрипторов. Количество классов определяет число нейронов в выходном слое (слое суммирования). Слой примеров формируется автоматически, исходя из количества примеров по каждому классу.
Перед подачей на вход сети векторы, представляющие тексты, нормируются с тем, чтобы их модули были равны. В противном случае сеть начинает обращать внимание на количество нулей и единиц в представляющем текст векторе, а не на их комбинацию.
Процесс обучения выглядит следующим образом (рис. 3).

Рис. 3.
Количество примеров, необходимых для обучения сети, определяется на основе следующей закономерности. Дело в том, что зависимость мощности словаря дескрипторов от количества примеров имеет вид, показанный на рис. 4.

Рис. 4.
Очевидно, что, начиная с некоторого момента, увеличение числа примеров не приводит к существенному изменению словаря. Следовательно, далее наращивать число примеров не имеет смысла.
Процесс классификации. Таким образом, полностью процесс
классификации текстов можно представить в виде схемы, показанной на рис. 5, где
pi –
вероятность того, что данный текст
принадлежит классу ![]() .
.
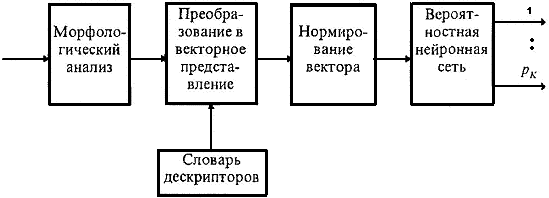
Рис. 5.
4. Практические результаты
В качестве исходных данных для проведения эксперимента использовались тексты сообщений средств массовой информации по трем рубрикам:
1) дефицит платежных средств;
2) социальная деятельность местных властей;
3)уголовная преступность.
В обучающий набор вошли по 200 сообщений на каждую рубрику. После формирования полного словаря его объем составил примерно 16000 слов. В результате усечения и редактирования объем словаря уменьшился до 1150 слов. Далее использовалась программная реализация вероятностной нейронной сети, имеющаяся в приложении к книге [3].
Для данной программы использовались следующие исходные данные:
модель сети...............основная,
ядро..........................Гауссиана,
число входов....................1150,
число выходов.......................3.
После обучения на вход системы было подано 250 ранее ей неизвестных текстов сообщений, принадлежащих первой рубрике. То же самое было проделано для остальных двух рубрик. Результаты классификации приведены в виде графиков (рис. 6).

Рис. 6.
По оси X отложены номера сообщений (всего 250), по оси Y - вероятность, с которой они были отнесены к соответствующей рубрике. Для наглядности сообщения упорядочены по значениям вероятности.
Из графиков видно, что правильно было классифицировано около 80-90 % текстов сообщений.
И, в заключение, несколько слов о временных затратах. На компьютере, оснащенном процессором Pentium-133 и 16 Мбайт оперативной памяти, для обучения сети потребовалось примерно 60 мин, скорость классификации составила около 100 сообщений/мин.
Список литературы
1. Comparing Vector Space Retrieval With The RUBRIC Expert System, SIGIR Forum, 1989, T. 23, № 1-2.
2. Donald Specht. Probabilistic Neural Networks. Neural Networks, 1990, № 1.
3. Timothy Masters. Advanced Algorithms For Neural Networks. John Wiley & Sons, 1995.
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ №7. 1997.
НЕЙРОСЕТИ И НЕЙРОКОМПЬЮТЕРЫ
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||