научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 04, апрель 2012
УДК 004.657
МГТУ им. Н.Э. Баумана
Введение
В настоящее время не существует научно обоснованного метода оценки и выбора архитектуры параллельной системы баз данных [2]. В предыдущих статьях [4, 15] рассмотрен математический метод анализа времени выполнения запроса к одной и двум таблицам параллельной системы баз данных (ПСБД). В данной работе демонстрируется применение математического аппарата производящих функций и преобразования Лапласа-Стилтьеса для оценки моментов времени выполнения соединения таблиц в ПСБД.
Получение такой оценки важна, так как операция соединения (join) часто используется в аналитических запросах к хранилищам данных, построенных на основе реляционных баз данных (ROLAP). Прогнозирование индексов производительности параллельных систем баз данных необходимо – соответствующие аппаратно-программные комплексы очень дороги и ошибки в их выборе приводят к большим финансовым потерям.
Варианты реализация параллельных систем баз данных
Наиболее распространенной системой классификации параллельных систем баз данных является система, предложенная Майклом Стоунбрейкером [2]. В соответствии с этой классификацией архитектуры подразделяются на следующие типы: SE (Shared-Everything) - архитектура с разделяемыми памятью и дисками; SD (Shared-Disks) - архитектура с разделяемыми дисками и соединительной сетью; SN (Shared-Nothing) - архитектура с разделяемой сетью.
Копеланд (Copeland) и Келлер (Keller) предложили расширение классификации Стоунбрейкера путем введения двух дополнительных классов архитектур параллельных машин баз данных: CE (Clustered-Everything) - архитектура с SE кластерами, объединенными по принципу SN; CD (Clustered-Disk) - архитектура с SD кластерами, объединенными по принципу SN.
На текущий момент наиболее часто применяемыми типами архитектур при построении высокопроизводительных параллельных систем является архитектура SE. Реже используются архитектуры SD, SNи CE. Реализаций архитектуры CD не известно. Приведем более подробное описание средств реализации архитектурных решений.
SE-архитектура представляет систему баз данных, в которой все диски напрямую доступны всем процессорам и все процессоры разделяют общую оперативную память. Доступ к дискам в системах SE обычно осуществляется через общий буферный пул. При этом следует отметить, что каждый процессор в системе SE имеет собственную кэш-память. Чаще всего эта архитектура реализуется на промышленных SMP-серверах, построенных на процессорах RISC. Примером реализации архитектуры SE может служить комплекс, состоящий из сервера SunEnterpriseM9000, системы хранения данных EMCSymmetrixDMX-4 и инфраструктуры сети хранения данных SAN[5].
SD-архитектура представляет систему баз данных, в которой любой процессор имеет доступ к любому диску, однако каждый процессор имеет свою приватную оперативную память. Процессоры в таких системах соединены посредством некоторой высокоскоростной сети. Системы SD чаще всего реализуется на промышленных серверах с процессорной архитектурой z/Architecture. Хотя по своему строению эти системы близки к архитектуре SMP-сервера, общая архитектура системы может изменяться с помощью программно-аппаратных средств ParallelSysplex, позволяющих множеству узлов работать с единой высокопроизводительной внешней системой хранения данных. Примером реализации архитектуры SD может служить комплекс, состоящий из двух серверов IBMz10, системы хранения данных IBMDS8800 и инфраструктуры FICON [6].
SN-архитектура характеризуется наличием у каждого процессора собственной оперативной памяти и собственной дисковой системы. Как и в системах SD , процессорные узлы соединены некоторой высокоскоростной сетью. К настоящему моменту создано большое количество исследовательских прототипов и несколько коммерческих систем с архитектурой SN , использующих фрагментный параллелизм на MPP-системах. Примером реализации архитектуры SN может служить комплекс TeradataDatabase [7, 8], который представляет собой совокупность SMP-систем (или простых однопроцессорных систем), построенных на базе процессоров Intelx86_64 и связанных между собой высокоскоростной внутренней сетью BYNET. Каждый узел имеет свою собственную оперативную память и дисковую систему. Так как сеть BYNET реализует межузловой обмен данными по технологии точка-точка, то в данной конфигурации нет разделяемых ресурсов. В этом комплексе в качестве СУБД может функционировать только СУБД Teradata.
В архитектуре CDкаждый узел представляет собой SD-систему. Используется дополнительное программное обеспечение, позволяющее осуществлять обмен метаданными между системами и арбитраж глобальных блокировок в СУБД и преобразующее весь комплекс к архитектуре CD. Примером реализации CD-архитектуры может служить комплекс из 4-серверов IBMSystemX 3950M2 и системы хранения данных HitachiUniversalStoragePlatformV[9].
Выполнение запросов в параллельной системе баз данных
Процесс выполнения SQL-запроса в параллельной системе баз данных можно представить в виде следующих шагов [2]:
· генерация последовательного плана выполнения запроса,
· тиражирование плана выполнения запроса на все узлы системы,
· обработка запроса над фрагментированными таблицами (распределение фрагментов таблиц БД по узлам системы выполняется заранее и один раз),
· слияние полученных данных.
Рассмотрим процесс параллельной обработки запроса, где выполняется соединение таблиц R и S базы данных (рис. 1). Q = R ⊳⊲ S – это логическая операция соединения (join) двух отношений (таблиц) R и S по некоторому общему атрибуту Y. В данном примере таблица R фрагментирована произвольным образом, а таблица S – по атрибуту соединения Y. На рис. 1 показано, что логический план выполнения соединения двух отношений тиражируется на 'n' процессоров в параллельной системе баз данных (на рисунке показаны 2 процессора). Далее происходит параллельная обработка на каждом процессоре соответствующих фрагментов таблиц R и S. Вследствие того, что таблица R не фрагментирована по атрибуту соединения, при последовательном чтении записей этой таблицы происходит их обработка в операторе exchange, осуществляющем разбор записи и её межпроцессорный обмен. Таблица Sфрагментирована по атрибуту соединения и записи читаемые из фрагментов этой таблицы обрабатываются на каждом процессоре локально.
Оператор exchange является составным оператором и включает в себя четыре оператора: gather, scatter, split и merge. Оператор split - это оператор, который осуществляет разбиение кортежей (записей), поступающих из входного потока, на две группы: свои и чужие. Свои кортежи - это кортежи, которые должны быть обработаны на данном процессорном узле. Эти кортежи направляются в выходной буфер оператора split (стрелка вверх). Чужие кортежи, то есть кортежи, которые должны быть обработаны на процессорных узлах, отличных от данного, помещаются оператором split во входной буфер правого дочернего узла, в качестве которого фигурирует оператор scatter. Нульарный оператор scatter извлекает кортежи из своего входного буфера и пересылает их на соответствующие процессорные узлы. Нульарный оператор gather выполняет перманентное чтение кортежей из указанного порта со всех процессорных узлов, отличных от данного. Оператор merge, реализующий логическую операцию join, определяется как бинарный оператор, который забирает кортежи из выходных буферов своих дочерних узлов, соединяет их и помещает результат в собственный выходной буфер. Таким образом, с помощью рассмотренных операций оператор exchange реализует полноценный межпроцессорный обмен записями в параллельной системе баз данных при обработке запроса методом фрагментарного параллелизма.
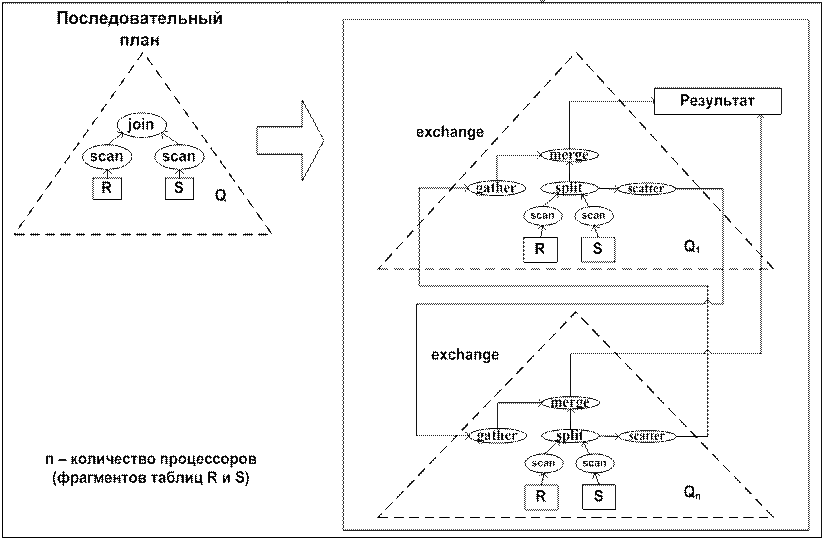
Рис. 1. Обработка запроса Q = R ⊳⊲ S в параллельной системе баз данных.
Оценка математического ожидания времени соединения таблиц
В работе [15] получены преобразования Лапласа-Стилтьеса (ПЛС) времени соединения таблиц Aи B методами NLJи HJ (алгоритм Grace):
![]() , (1)
, (1)
 , (2)
, (2)
где
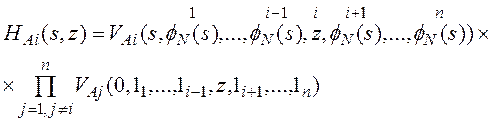 , (3)
, (3)
![]() , (4)
, (4)
![]() - это производящая функция числа записей, удовлетворяющих условию поиска по таблице A (с вероятностью PA),
- это производящая функция числа записей, удовлетворяющих условию поиска по таблице A (с вероятностью PA),
![]() определяется следующими рекуррентными формулами:
определяется следующими рекуррентными формулами:
![]() ,
,
![]()
... (5)
![]() ,
, ![]() ,
,
pAij - это вероятность, что запись передаётся из i-го узла в j-й узел при условии, что она не была передана в узлы n...j+1,
![]() - производящая функция числа записей таблицы B, удовлетворяющих условию поиска по таблице B (вероятность PB) и условию соединения (вероятность ηAB),
- производящая функция числа записей таблицы B, удовлетворяющих условию поиска по таблице B (вероятность PB) и условию соединения (вероятность ηAB),
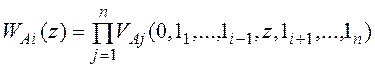 , (6)
, (6)
r – число разделов (хеш-групп) в хеш-таблице,
показатели степени ωA≤ 2 и ωB≤ 2 определяют число чтений/записей на диск хеш-групп.
В приведённых выше формулах встречаются ПЛС φD(s), ![]() ,φP(s) и φN(s). Они имеют следующий смысл [4]:
,φP(s) и φN(s). Они имеют следующий смысл [4]:
φD(s) - ПЛС времени чтения записи БД из подсистемы ввода/вывода,
![]() - ПЛС времени записи и последующего чтения записи БД из ОП,
- ПЛС времени записи и последующего чтения записи БД из ОП,
φP(s) - ПЛС времени обработки записи БД в процессоре,
φN(s) - ПЛС времени передачи записи БД по высокоскоростной шине, связывающей процессоры системы.
В табл. 1 приведены выражения для указанных преобразований для различных архитектурных решений [15].
Таблица 1
| SE | SD | SN |
|
|
| |
|
(обмен между процессорами осуществляется через ОП) |
| |
|
| ||
|
| ||


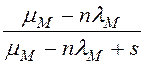

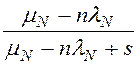
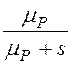
Здесь n – процессоров (узлов) в параллельной системе баз данных, λ и μ – интенсивности поступления записей от одного процессора и их обработки в соответствующем ресурсе (D - внешней памяти, M - ОП, P - процессоре, N - шине), L– среднее число записей, читаемых из RAID-массива за одно многоблочное чтение при сканировании таблицы СУБД. По существу величина (1-1/L) – это вероятность чтения записи из общесистемного буфера СУБД (т.е. из кэша).
Наличие произведения 'nλ' в ПЛС означает, что ресурс является разделяемым в соответствующей архитектуре (т.е. к нему возможна очередь). Хотя поведение параллельной системы баз данных при выполнении запроса описывается в виде замкнутой системы массового обслуживания (СМО), но, как видно из табл. 1, здесь в качестве модели разделяемого ресурса используется разомкнутая СМО M/M/1.
Дифференцируя выражения (1) и (2) как сложные функции по sв нуле, можно получить моменты случайного времени (ξ) обработки запроса в параллельной системе баз данных (ПСБД) для различных способов соединения таблиц (NLJ и HJ):
![]() ,
, ![]() ,
, ![]() . (7)
. (7)
После дифференцирования с учётом выражений, приведённых в табл. 1, получим следующие формулы для расчёта математических ожиданий времени выполнения соединения таблиц для различных архитектур ПСБД [15]:
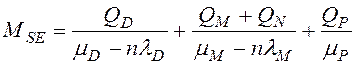 , (8)
, (8)
 , (9)
, (9)
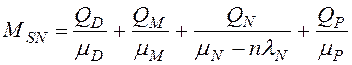 . (10)
. (10)
Здесь и далее индекс ξ будем опускать. Выражения для QD, QM, QN, QP для методов соединения NLJ и HJ приведены в табл. 2 [15]. При получении формул для HJ предполагалось, что хэш-таблица создающей таблицы A полностью сохраняется в оперативной памяти. Это сделано только для того, чтобы упростить выражения (в этом случае ωA=ωB=0).
Таблица 2
| NLJ | HJ |
QD |
|
|
QP |
| |
QM |
|
|
QN |
| |

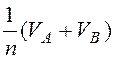



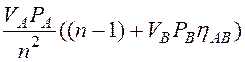
Параметры, используемые в формулах табл.2, определены ранее. Прямой расчёт по формулам (8) и (9) затруднён, так как достаточно сложно одновременно оценить параметры λD и λM разделяемых ресурсов (диска и ОП). Но в системе из двух таких ресурсов, как правило, только один из них является "узким местом" (обычно это диск). Т. е. в среднем в нём накапливается требований намного больше, чем в другом разделяемом ресурсе. Наличие "узкого места" легко определить (табл. 3). В этом случае другой разделяемый ресурс можно считать неразделяемым. Тогда замкнутая модель ПСБД сводится к модели "ремонтника", которая при достаточно больших 'n' близка по характеристикам к СМО М/М/1 с интенсивностью входного потока nλ. Параметр λ легко рассчитывается (см. табл. 3 [15]). Расчётные формулы для математического ожидания представлены в последней колонке табл. 3. Эти формулы отличаются от выражений (8) и (9) тем, что для некритического разделяемого ресурса отсутствует произведение nλ, т.е. этот ресурс считается неразделяемым.
Таблица 3
| Условие наличия "узкого места" | "Узкое место" | Определяемый параметр λ | Формула для оценки λ | Формула для оценки математического ожидания (МО) времени выполнения соединения двух таблиц |
SE |
| Диск | λD |
|
|
| Память | λM |
|
| |
SD |
| Диск | λD |
|
|
| Сеть | λN |
|
| |
SN | нет | Сеть | λN |
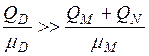


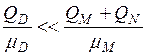








Расчёты по формулам, приведённым в табл.3, следует выполнять в следующей последовательности ]15]:
1. Выбрать требуемую архитектуру – колонка 1.
2. Выявить "узкое место" системы (оно, как правило, присутствует, так как загрузки ресурсов невозможно сбалансировать) – колонки 2, 3.
3. Рассчитать параметр λ для "узкого места" – колонки 4, 5.
4. Если для "узкого места" выполняется неравенство (nλ/μ)≥1, то уменьшить число процессоров nи повторить пункт 4. Если это неравенство выполняется и для n=1, то считать данное архитектурное решение неудачным, так как в этом случае все требования будут ждать обслуживания в разделяемом ресурсе ("узкое место" очень медленное) и процессоры будут простаивать. Иначе перейти к пункту 5.
5. Рассчитать математическое ожидание времени выполнения запроса в ПСБД – колонка 6.
Пример расчёта среднего времени соединения таблиц
Расчёт математического ожидания (среднего) времени соединения таблиц в ПСБД [15] был выполнен при следующих значениях характеристик ресурсов.
1. Процессор – IntelXeon 5160. СУБД – Oracle 9i. В [3, стр. 347] приведены результаты автотрассировки простого запроса соединения: число обработанных записей в двух таблицах – 640, число процессорных циклов - 7 106. В [14] для выбранного процессора приведено измеренное значение числа процессорных циклов, выполняемых Oracleв секунду (CPUSPEED) – 1.5×109. Поэтому для интенсивности обработки записей в процессоре имеем – μP= 640/(7×106/1.5×109)=1,3×105.
2. Внешняя память – RAID10 cКД=10 дисками 3.5'' SeagateCheetah 15K.6 ST3146356FC; размер блока чередования (stripesize) – QБЧ=256 Kб; среднее время поиска и чтения блока чередования с диска – tБЧ = tподвода + tвращения/2 + QБЧ/vчтения = 4 + 4/2 + 256/200 = 7 мс.
Размер блока СУБД – QБС=16 Кб; средняя длина записи таблиц А и В – lЗ=0.256 Кб, размер многоблочного чтения СУБД (переменная СУБД db_file_multiblock_read_count) - qМБ=80. Поэтому для интенсивности чтения записей БД из массива RAID имеем – μD= qМБ ×QБС/lЗ/(éqМБ ×QБС /QБЧ/(КД/2)ù ×tБЧ)= 0.7×106. Число 2 в этой формуле учитывает тот факт, что при чтении полосы RAID-массива (т.е. при одновременном чтении блоков чередования с разных дисков) используется половина дисков массива, так как в RAID10 каждый диск из этой половины имеет зеркальную копию.
3. Оперативная память – DDR3-1600 PC3- 12800. Расчёты показывают, что интенсивность чтения записей базы данных из ОП равна μM= 10.4×106.
4. Высокоскоростная системная шина: для SD - ParallelSysplex 12xQDR, для SN - ByNet. В обоих случаях узлы соединены по схеме "точка-точка" (т.е. шина является неразделяемым ресурсом) и интенсивность передачи записей по этим шинам равна μN= 50.3×106.
Далее приведены значения остальных параметров: число записей в таблицах Aи B– VA=VB=106, вероятность фильтрации записей таблиц Aи B – PA=PB=10-3 , вероятность успешного соединения двух записей – ηAB= 10-4, количество хеш-групп в методе соединения HJ– r=10.
При расчётах использовались формулы из табл. 3 и 2. Для архитектур SEи SD "узким местом" является внешняя память (диск). При вычислениях величину 'nλD' необходимо разделить на 2, так как при обработке запросов на чтение от разных процессоров может быть использована не только основная, но и зеркальная половина дисков. Для архитектуры SNпроизведение 'nλN' необходимо исключить из формулы расчёта математического ожидания (т.е. обнулить 'nλN' в колонке 6 табл. 3 для строки SN), так как в рассматриваемом примере шина является неразделяемым ресурсом. Графики зависимости математического ожидания времени выполнения соединения двух таблиц от числа процессоров 'n' в параллельной системе баз данных приведены на рис. 2, 3 [15].
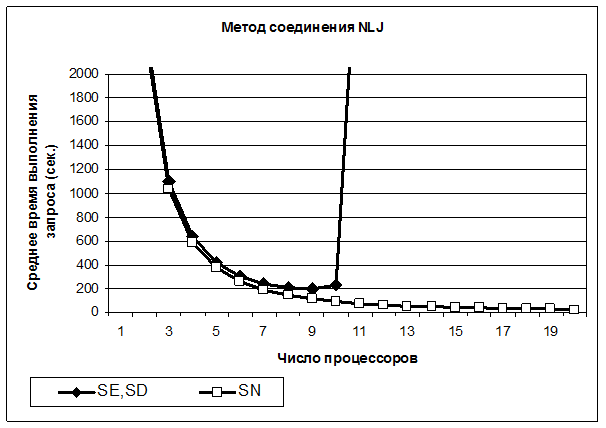
Рис. 2. Зависимость математического ожидания времени выполнения соединения таблиц в архитектурах SE, SD и SN методом NLJ от числа процессоров.

Рис. 3. Зависимость математического ожидания времени выполнения соединения таблиц в архитектурах SE, SD и SN методом HJ от числа процессоров.
Анализ графиков позволяет сделать несколько выводов [15]:
1. Графики для архитектур SESD практически совпали. Это объясняется высокими значениями интенсивностей μMи μN.
2. При n≥3 среднее время для метода соединения HJна два порядка меньше среднего времени для NLJ (это и следовало ожидать для неиндексированной по атрибуту соединения вложенной таблицы B). Более того, МNLJ(1)≈9400 с., МHJ(1)≈19 с.
3. При n≤ 7 архитектуры SEи SDне на много хуже SN. Следует также отметить, что при n=7 загрузка диска для SEи SDравна 0,63.
4. Для SEи SDпри n=11 перегружается дисковая подсистема, и дальнейший рост числа процессоров не имеет смысла. Для архитектуры SN время продолжает уменьшаться с ростом n (здесь нет разделяемых ресурсов). Однако следует иметь в виду, что для снижения времени выполнения соединения методом HJ с 2 секунд до 1 необходимо увеличить количество процессов с 10 до 20 (см. рис. 3), а это может оказаться экономически не целесообразным.
Таким образом, в работе приведены выражения для математических ожиданий времени выполнения операции соединения для методов NLJи HJ. Рассмотрен практический пример расчёта, позволивший сделать рад нетривиальных выводов.
ЛИТЕРАТУРА
1. М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных: [Электронный ресурс]. [http://citforum.ru/database/classics/distr_and_paral_sdb/]. Проверено 26.11.2010.
2. Соколинский Л. Б., Цымблер М. Л. Лекции по курсу "Параллельные системы баз данных”: [Электронный ресурс]. [http://pdbs.susu.ru/CourseManual.html]. Проверено 04.12.2010.
3. Дж. Льюис. Oracle. Основы стоимостной оптимизации. – СПб: Питер, 2007. – 528 с.
4. Григорьев Ю.А., Плужников В.Л. Оценка времени выполнения запросов и выбор архитектуры параллельной системы баз данных// Информатика и системы управления. – 2009. - № 3. – С. 3-12.
5. Производительность СУБД Oracle Database 11g при работе на сервере Sun SPARC Enterprise M9000: [Электронный ресурс]. [http://ru.sun.com/sunnews/press/2010/2010-05-18.jsp]. Проверено 26.11.2010
6. В.А. Варфоломеев, Э.К. Лецкий, М.И. Шамров, В.В. Яковлев. Лекции по курсу “Операционные системы и программное обеспечение на платформе zSeries”: [Электронный ресурс]. [http://www.intuit.ru/department/os/ibmzos/]. Проверено 26.11.2010.
7. Керри Болинджер. Врожденный параллелизм: [Электронный ресурс]. [http://www.osp.ru/ os/2006/02/1156526/_p1.html]. Проверено 26.11.2010.
8. Лев Левин. Teradata совершенствует хранилища данных: [Электронный ресурс]. [http://www.pcweek.ru/themes/detail.php?ID=71626]. Проверено 26.11.2010.
9. Oracle Real Application Clusters Administration and Deployment Guide 11g Release 1 (11.1): [Электронныйресурс]. [http://download.oracle.com/docs/cd/B28359_01/rac.111/ b28254/admcon.htm/]. Проверено 26.11.2010.
10. Григорьев Ю.А., Плутенко А.Д. Теоретические основы анализа процессов доступа к распределённым базам данных. - Новосибирск: Наука, 2002. – 180 с.
11. Жожикашвили В.А, Вишневский В.М. Сети массового обслуживания. Теория и применение к сетям ЭВМ. – М.: Радио и связь, 1988. – 192 с.
12. Клейнрок Л. Теория массового обслуживания. – М.: Машиностроение, 1979. – 432 с.
13. Бронштейн О.И., Духовный И.М. Модели приоритетного обслуживания в информационно-вычислительных системах. – М.: Наука, 1976. – 220 с.
14. Форум/Использование СУБД/Oracle/CPUSPEEDна IntelXeon 5500 (Nehalem): [Электронный ресурс]. [http://www.sql.ru]. Проверено 02.12.2010.
15. Григорьев Ю.А., Плужников В.Л. Оценка времени соединения таблиц в параллельной системе баз данных// Информатика и системы управления. – 2011. - № 1. – С. 3-16
Публикации с ключевыми словами: преобразование Лапласа-Стилтьеса, математическое ожидание времени выполнения запроса, параллельная система баз данных, соединение таблиц, архитектуры SE, SD, SN, методы соединения таблиц NLJ и HJ
Публикации со словами: преобразование Лапласа-Стилтьеса, математическое ожидание времени выполнения запроса, параллельная система баз данных, соединение таблиц, архитектуры SE, SD, SN, методы соединения таблиц NLJ и HJ
Смотри также:
- 77-30569/387243 Анализ процессов выполнения запросов в параллельных системах баз данных с архитектурами SE, SD, SN
- Преобразование Лапласа-Стилтьеса времени соединения двух таблиц в параллельной системе баз данных
- 77-30569/241916 Оценка среднего времени обработки запросов к хранилищу данных методом создания первичного индекса для таблицы фактов в параллельной системе баз данных
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||