научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 11, ноябрь 2011
УДК 004.657
МГТУ им. Н.Э. Баумана
В работах [11, 12] получено преобразование Лапласа-Стилтьеса (ПЛС) времени выполнения запроса к хранилищу данных, которое справедливо для каждого АМР параллельной системы баз данных:
![]() , (1)
, (1)
где
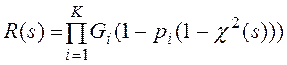 , (2)
, (2)
K – число измерений,
 - производящая функция числа записей i-го измерения в узле,
- производящая функция числа записей i-го измерения в узле,
Vi – общее число записей i-го измерения,
n – число AMP- узлов (AMP-процессоров),
pi - вероятность, что запись i-го измерения удовлетворяет условию поиска по этому измерению в запросе,
χ2(s) - ПЛС времени обработки записи блока листового уровня индекса (χ(s)) и записи таблицы измерения (χ(s)),
![]() , (3)
, (3)
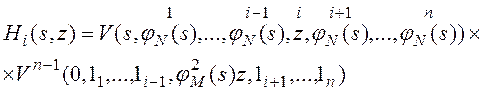 , (4)
, (4)
![]() , (5)
, (5)
![]() ,
,
![]() , (6)
, (6)
![]() ,
,
![]() определяется следующими рекуррентными формулами:
определяется следующими рекуррентными формулами:
![]() ,
,
![]() ,
,
(7)
![]() ,
, ![]() ,
,
pj - это вероятность, что запись передаётся из данного узла в j-й узел при условии, что она не была передана в узлы n...j+1.
В табл. 1 [11, 12] приведены выражения для ПЛС φD(s), φM(s), φN(s), φPI(s), φPJ(s), φPA(s), φPS(s) – это ПЛС случайного времени обработки записи (исходной, промежуточной, результирующей) в ресурсе (диске, ОП, шине, процессоре).
Таблица 1
| SE | SD | SN |
φD(s) |
|
| |
φM(s) |
(обмен между процессорами осуществляется через ОП) |
| |
φN(s) |
| ||
φPI(s), φPJ(s), φPA(s), φPS(s) |
| ||
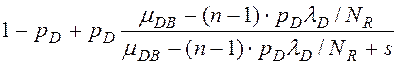
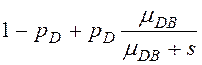

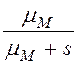
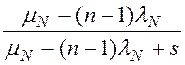
 ,
, 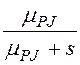
 ,
, 
Здесь
1-pD – вероятность, что запись находится в кэше (СУБД или диска),
λD, λM, λN – интенсивности запросов к разделяемому ресурсу (на чтение записей из RAID-массива, на запись/чтение записей таблиц из ОП, на передачу записей по соединительной шине),
μDB=1/tБЧ – интенсивность чтения блоков чередования с диска RAID-массива, tБЧ - среднее время чтения блока чередования,
NR – количество дисков в RAID-массиве (с учётом зеркальных),
μM – интенсивность записи/чтения записей таблиц из ОП,
μN – интенсивность передачи записей по соединительной шине,
μPI– интенсивность обработки записей в процессоре при их поиске и чтении с помощью индекса,
μPJ– интенсивность построения записей декартова произведения в процессоре,
μPS– интенсивность сравнений записей БД в процессоре при их сортировке,
μPA– интенсивность агрегации записей (значений фактов),
QPS – значение коэффициента при среднем значении . ![]() (см. ниже),
(см. ниже),
(n-1) в табл. 1 означает, что заявка не ждёт сама себя в очереди к ресурсу.
В дальнейшем будем считать, что запись результирующего декартова произведения остаётся в данном узле или передаётся в другие узлы с одинаковой вероятностью. Т. е. pj= 1/j в формулах (7). В этом случае в формуле (5)
 . (8)
. (8)
Продифференцируем выражение (1) в нуле и оценим математическое ожидание времени выполнения запроса к ROLAP в параллельной системе баз данных [11, 12]. При этом индекс i будем опускать в силу симметричности (8).
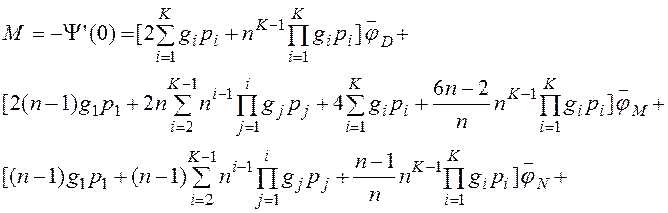
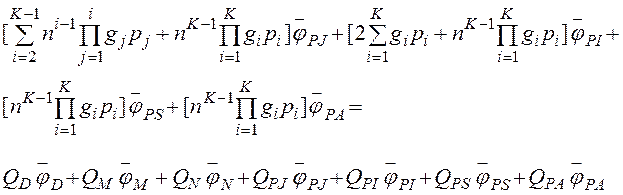 (9)
(9)
где ![]() и т.д. определяются следующим образом [4]:
и т.д. определяются следующим образом [4]:
- если соответствующий ресурс является "узким местом" (табл. 2), то это математическое ожидание времени пребывания в ресурсе, ПЛС которого представлено в табл. 1 (где фигурирует соответствующая интенсивность запросов к ресурсу - λD и т.д.),
- в противном случае 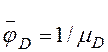 и т.д. (для неразделяемого ресурса и для разделяемого ресурса, который не является "узким местом"),
и т.д. (для неразделяемого ресурса и для разделяемого ресурса, который не является "узким местом"),
![]() - математическое ожидание числа записей таблицы i-го измерения, которые хранятся в узле.
- математическое ожидание числа записей таблицы i-го измерения, которые хранятся в узле.
Остальные переменные в формуле (9) определены выше. Формулы для оценки λD, λM, λN приведены в табл. 2 [11].
Таблица 2
Архитектура | Условие наличия "узкого места" | "Узкое место" | Определяемый параметр λ | Формула для оценки λ |
SE |
| Диск | λD |
|
| Память | λM |
| |
SD |
| Диск | λD |
|
| Сеть | λN |
| |
SN | нет | Сеть | λN |


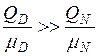
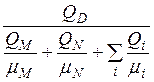
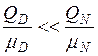

В табл. 2 введено следующее обозначение:
 (10)
(10)
Помимо архитектур SE, SD и SN на практике применяют смешанные архитектурные решения. Например, узлы SMP (SE) соединяются по схеме "точка-точка" типа ByNet (SN). В этом случае формулу (9) можно переписать в следующем виде:
 , (11)
, (11)
здесь предполагается, что в SMP-узле "узким местом" является диск,
nAMP– число AMP-процессоров (узлов) в одном SMP-узле,
n= nSMP×nAMP - общее число AMP-процессоров в системе,
nSMP - число SMP-узлов,
Г(n) – вектор (g1(n), ..., gK(n)),
 - среднее время передачи записи между AMP-процессорами SMP-узла (чтение из ОП – передача записи (сообщения) по системной шине – запись в ОП),
- среднее время передачи записи между AMP-процессорами SMP-узла (чтение из ОП – передача записи (сообщения) по системной шине – запись в ОП),
остальные обозначения такие же, как и в формуле (9).
Пример расчёта среднего времени выполнения запроса к хранилищу данных в параллельной системе баз данных
Расчёт математического ожидания (среднего) времени выполнения запроса к хранилищу данных в ПСБД был выполнен при следующих значениях характеристик ресурсов.
1. Процессор – IntelXeon 5160. СУБД – Oracle 9i. В [9] для выбранного процессора приведено измеренное значение числа процессорных циклов, выполняемых Oracle в секунду (CPUSPEED) – 1.5×109.
Согласно [3, стр. 228-230] при поиске и чтении 400 записей с помощью обычного индекса (B-дерева) было потрачено 6×105 процессорных циклов. Для интенсивности обработки записей в процессоре при их поиске и чтении с помощью индекса имеем - μPI= 400/(6×105/1.5×109)= 106.
В [3, стр. 347] приведены результаты автотрассировки простого запроса соединения: число обработанных записей во внешней таблице– 320, число процессорных циклов - 7×104. Поэтому для интенсивности построения записей декартова произведения в процессоре имеем – μPJ= 320/(7×104/1.5×109)= 7×106.
Согласно [3, стр. 397, 400] на выполнение 2×107 сравнений при сортировке записей БД в оперативной памяти было потрачено 6,21 секунд процессорного времени при скорости 3,5×108 процессорных тактов в секунду (CPUSPEED). Поэтому для интенсивности сравнений записей БД в процессоре при их сортировке имеем - μPS= 2×107 × (1.5×109/3,5×108)/6,21 = 14×106.
Интенсивность агрегации записей (значений фактов) μPA= μPS= 14×106 (т.к. многие операции агрегирования фактов требуют сортировки – orderby, groupby и др.
2. Оперативная память (ОП) – DDR3-1600 PC3- 12800. Расчёты показывают, что интенсивность записи/чтения записей таблиц из ОП равна μM= 10.4×106 (она мало зависит от длины записи, т.к. данные читаются страницами из ОП).
3. Высокоскоростная системная шина:
для SE (SMP) – системная шина QuickPathInterconnect, её производительность достигает 25 Гбайт/с; при средней длине записи lЗ= 100 байтов интенсивность передачи записей по шине равна μN= 250×106; при такой скорости эта шина не будет "узким местом" в архитектуре SE,
для SD (кластерная архитектура) и SN (MPP) - в обоих случаях узлы соединены по схеме "точка-точка" типа ByNet (т.е. шина является неразделяемым ресурсом) и интенсивность передачи данных по этой шине равна 20 Мбайт/с на один узел. Таким образом, при средней длине записи lЗ= 100 байтов интенсивность передачи записей по соединительной шине равна μN= 0.2n×106.
2. Внешняя память – RAID10 cNR=30 дисками (с учётом зеркальных) 3.5'' SeagateCheetah 15K.6 ST3146356FC (объём диска 147 Гбайт); размер блока чередования (stripesize) – QБЧ=64 Kбайт; среднее время поиска и чтения блока чередования с диска – tБЧ = tподвода + tвращения/2 + QБЧ/vчтения = 4 + 4/2 + 64/200 = 6,3 мс. Следовательно, μDB=1/tБЧ=1.6×102.
При расчётах использовались формула (11), а также формулы из табл. 1 и 2. Графики зависимостей математического ожидания (среднего) времени выполнения запроса к хранилищу данных (М) от общего числа процессоров 'n' в параллельной системе баз данных приведены на рис. 1.
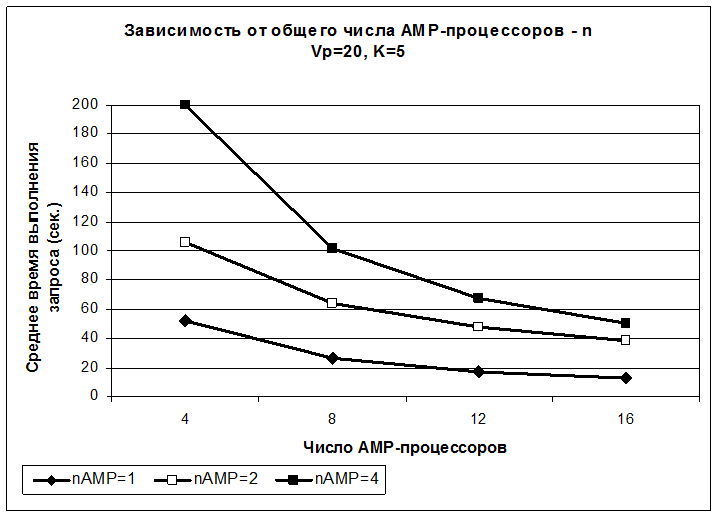
Рис. 1. Зависимости математического ожидания времени выполнения запроса к хранилищу данных (М) от числа процессоров (n).
Графики построены при следующих параметрах: среднее число записей таблиц измерений в запросе - Vipi= Vp= 20, число измерений - K=5 (число записей в декартовом произведении измерений равно 205), вероятность, что запись находится в кэше (СУБД или диска) - 1-pD= 0,99. Каждая зависимость соответствует конкретному числу AMP-процессоров в одном SMP-узле: nAMP= 1 (SN), 2, 4 (см. легенду). При этом число SMP-узлов равно nSMP= n/nAMP.
Анализ зависимостей на рис. 1 позволяет сделать следующие выводы:
1. Перегрузка диска в SMP-узле наступает при nAMP= 4, в этом случае среднее время обработки одной записи в дисковой подсистеме узла рассчитывалось по формуле
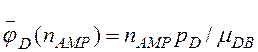 . (12)
. (12)
Уменьшение времени выполнения запроса при nAMP= 4 с ростом общего числа AMP-процессоров объясняется уменьшением числа записей таблиц измерений и фактов, хранящихся в одном SMP-узле.
2.Дл случая nAMP= 4 при n=16 (число SMP-узлов равно 4) время выполнения запроса (50 сек.) соизмеримо с временем выполнения запроса в SN(MPP)-системе (nAMP= 1) при n=16 (13 сек.). Но такая смешанная SMP-система в несколько раз дешевле (примерно в 4 раза) соответствующей SN(MPP)-системы.
3. В рассматриваемом примере время выполнения запроса в "чистой" SMP-системе (nSMP= 1) не зависит от 'n' и равно примерно 200 с. Это подтверждает тот факт, что при перегрузке "узкого места" (диска) не имеет смысла наращивать число AMP-процессоров в "чистой" SMP-системе.
Графики зависимостей математического ожидания (среднего) времени выполнения запроса к хранилищу данных (М) от среднего числа записей таблиц измерений в запросе (Vipi= Vp) в параллельной системе баз данных приведены на рис. 2.
Графики на рис. 2 построены при следующих параметрах: общее число AMP-процессоров – n= 16, число AMP-процессоров в узле – nAMP= 1 (SN(MPP)-система, см. сплошные линии), вероятность, что запись находится в кэше (СУБД или диска) - 1-pD= 0,99. Одна зависимость соответствует числу измерений в запросе: K= 3, 4, 5(см. легенду).
Анализ зависимостей на рис. 2 позволяет сделать следующие выводы:
1. Время выполнения запроса сильно зависит от числа записей в измерении (Vp) и числа измерений (K), указанных в запросе. MPP-системе с 16 AMP-процессорами потребуется 19 часов, чтобы обработать записи 5-ти измерений по 110 записей в каждом измерении (количество записей в декартовом произведении равно 1105). Чтобы снизить это время до 19 минут потребуется MPP-система с 1000 AMP-процессорами.
2. Системе с 4-я SMP-узлами по 4-е AMP-процессора в каждом узле (см. пунктирную линию на рис. 2) потребуется 72 часа, чтобы обработать записи 5-ти измерений по 110 записей в каждом измерении.

Рис. 2. Зависимости математического ожидания времени выполнения запроса к хранилищу данных (М) от среднего числа записей таблиц измерений в запросе (Vipi= Vp).
В работе проанализирован процесс обработки запроса к хранилищу данных, реализованному на основе параллельной системы баз данных и использующему специальный план соединения таблиц измерений и фактов.
Приведено выражение для математического ожидания времени выполнения запроса. Рассмотрен практический пример расчёта и сделаны некоторые выводы. В частности, если "узкое место" (диск) системы не перегружено (его загрузка меньше 1), то среднее время выполнения запроса к хранилищу данных в системе с SMP-узлами соизмеримо с временем обработки этого запроса в MPP-системе с тем же количеством AMP-процессоров. Это позволяет существенно сэкономить денежные средства при приобретении аппаратного обеспечения параллельной системы баз данных.
ЛИТЕРАТУРА
1. М. Тамер Оззу, Патрик Валдуриз. Распределенные и параллельные системы баз данных: [Электронный ресурс]. [http://citforum.ru/database/classics/distr_and_paral_sdb/]. Проверено 26.11.2010.
2. Соколинский Л. Б., Цымблер М. Л. Лекции по курсу "Параллельные системы баз данных”: [Электронный ресурс]. [http://pdbs.susu.ru/CourseManual.html]. Проверено 04.12.2010.
3. Дж. Льюис. Oracle. Основы стоимостной оптимизации. – СПб: Питер, 2007. – 528 с.
4. Григорьев Ю.А., Плужников В.Л. Оценка времени соединения таблиц в параллельной системе баз данных// Информатика и системы управления. – 2011. - № 1. – С. 3-16.
5. Лисянский К., Слободяников Д. СУБД Teradata® для ОС UNIX®: [Электронный ресурс]. [http://citforum.ru/database/kbd98/glava5.shtml]. Проверено 14.03.2011.
6. КузнецовС. Essential Modelling Options: [Электронныйресурс]. [http://citforum.ru/database/digest/dig_1612.shtml]. Проверено 14.03.2011.
7. Лев Левин. Teradata совершенствует хранилища данных: [Электронный ресурс]. [http://www.pcweek.ru/themes/detail.php?ID=71626]. Проверено 26.11.2010.
8. Григорьев Ю.А., Плутенко А.Д. Теоретические основы анализа процессов доступа к распределённым базам данных. - Новосибирск: Наука, 2002. – 180 с.
9. Форум/Использование СУБД/Oracle/CPUSPEED на IntelXeon 5500 (Nehalem): [Электронный ресурс]. [http://www.sql.ru]. Проверено 02.12.2010.
10. Миллер Р., Боксер Л. Последовательные и параллельные алгоритмы. Общий подход. – М.: БИНОМ. Лаборатория знаний, 2006. – 406 с.
11. Григорьев Ю.А., Плужников В.Л. анализ времени обработки запросов к хранилищу данных в параллельной системе баз данных // Информатика и системы управления. – 2011. - № 2. – С. 94-106.
12. Плужников В.Л. Преобразование Лапласа-Стилтьеса времени обработки запросов к хранилищу данных в параллельной системе баз данных: [Электронный ресурс]. [http://technomag.edu.ru/doc/270159.html]. Проверено 29.10.2011.
Публикации с ключевыми словами: хранилище данных, преобразование Лапласа-Стилтьеса, математическое ожидание времени выполнения запроса, параллельная система баз данных, первичный индекс, архитектуры SE, SD, SN, CE
Публикации со словами: хранилище данных, преобразование Лапласа-Стилтьеса, математическое ожидание времени выполнения запроса, параллельная система баз данных, первичный индекс, архитектуры SE, SD, SN, CE
Смотри также:
- 77-30569/387243 Анализ процессов выполнения запросов в параллельных системах баз данных с архитектурами SE, SD, SN
- 77-30569/380603 Оценка среднего времени выполнения соединения таблиц методами NLJ и HJ в параллельной системе баз данных
- Оценка времени выполнения запроса в параллельной системе баз данных
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||