научное издание МГТУ им. Н.Э. Баумана
НАУКА и ОБРАЗОВАНИЕ
Издатель ФГБОУ ВПО "МГТУ им. Н.Э. Баумана". Эл № ФС 77 - 48211. ISSN 1994-0408
# 01, январь 2010
DOI: 10.7463/0110.0135375
МГТУ им. Н.Э. Баумана, 105005, Москва, 2-я Бауманская ул., д.5.,
тел.: (499)263-65-26,
E-mail: karpenko@nog.ru,
dmitry_moor@mail.ru,
D.Mukhlisullina@mail.ru
Введение
Рассматривается метод решения задачи многокритериальной оптимизации (МКО-задачи), который относится к классу адаптивных методов [1]. Каждая итерация этих методов включает в себя фазу анализа, выполняемую лицом, принимающим решения (ЛПР), и фазу расчетов, выполняемую системой многокритериальной оптимизации (МКО-системой).
По характеру информации, получаемой МКО-системой от ЛПР на фазе анализа, выделяются несколько классов адаптивных методов. В работе рассматриваются прямые адаптивные методы [1], в основе которых лежит предположение, что ЛПР может непосредственно выполнять оценку (например, в терминах «лучше», «хуже», «одинаково») предлагаемых МКО-системой альтернатив.
Прямой адаптивный метод решения МКО-задачи, который исследуется в данной работе, основан на предположении существования «функции предпочтений ЛПР» ![]() , которая определена на множестве
, которая определена на множестве ![]() допустимых значений вектора варьируемых параметров
допустимых значений вектора варьируемых параметров ![]() и выполняет отображение этого множества на множество действительных числе R. При этом задача многокритериальной оптимизации сводится к задаче выбора вектора
и выполняет отображение этого множества на множество действительных числе R. При этом задача многокритериальной оптимизации сводится к задаче выбора вектора ![]() такого, что
такого, что
![]() ,
, ![]() .
.
Предполагается, что при предъявлении ЛПР вектора параметров X, а также значений всех частных критериев оптимальности ![]() , это лицо может оценить соответствующее значение функции предпочтений
, это лицо может оценить соответствующее значение функции предпочтений ![]() .
.
В работе [2] предложен класс прямых адаптивных методов решения МКО-задачи, основанных на аппроксимации функции ![]() . Использование для аппроксимации функции
. Использование для аппроксимации функции ![]() нейронных сетей рассмотрено в работах [3, 4]. В данной работе рассматривается использование для этой цели аппарата нечеткой логики [5].
нейронных сетей рассмотрено в работах [3, 4]. В данной работе рассматривается использование для этой цели аппарата нечеткой логики [5].
В первом разделе работы приводится постановка МКО-задачи. Во втором разделе излагается схема метода. В третьем разделе обсуждается алгоритм и некоторые детали программной реализации метода. Четвертый раздел посвящен экспериментальному исследованию погрешности нечеткой аппроксимации функции предпочтений ЛПР. В заключении формулируются основные выводы.
1. Постановка МКО-задачи
Пусть ![]() - вектор варьируемых параметров задачи. Множеством допустимых значений вектора Xявляется ограниченное и замкнутое множество
- вектор варьируемых параметров задачи. Множеством допустимых значений вектора Xявляется ограниченное и замкнутое множество ![]() , где
, где
![]() -
-
«технологический» параллелепипед допустимых значений вектора параметров; множество ![]() формируют ограничивающие функции
формируют ограничивающие функции ![]() , так что
, так что
![]() ;
;
![]() - n-мерное арифметическое пространство.
- n-мерное арифметическое пространство.
Векторный критерий оптимальности ![]() со значениями в критериальном пространстве
со значениями в критериальном пространстве ![]() определен в параллелепипеде П. ЛПР стремится минимизировать на множестве
определен в параллелепипеде П. ЛПР стремится минимизировать на множестве ![]() каждый из частных критериев оптимальности
каждый из частных критериев оптимальности ![]() , что условно записывается в виде
, что условно записывается в виде
![]() ,
, ![]() , (1)
, (1)
где ![]() - искомое решение МКО-задачи. Частные критерии оптимальности полагаются нормализованными (тем или иным образом), так что
- искомое решение МКО-задачи. Частные критерии оптимальности полагаются нормализованными (тем или иным образом), так что ![]() ,
, ![]() .
.
Обозначим ![]() операцию свертки частных критериев оптимальности, где
операцию свертки частных критериев оптимальности, где ![]() - вектор весовых множителей;
- вектор весовых множителей; ![]()
![]() - множество допустимых значений этого вектора.
- множество допустимых значений этого вектора.
При каждом фиксированном векторе ![]() метод скалярной свертки сводит решение задачи (1) к решению однокритериальной задачи глобальной условной оптимизации (ОКО-задачи)
метод скалярной свертки сводит решение задачи (1) к решению однокритериальной задачи глобальной условной оптимизации (ОКО-задачи)
![]() ,
, ![]() . (2)
. (2)
Отметим, что в случае аддитивной свертки ![]() вектор
вектор ![]() принадлежит множеству эффективных по Парето векторов [1]. Для произвольной скалярной свертки вектор
принадлежит множеству эффективных по Парето векторов [1]. Для произвольной скалярной свертки вектор ![]() , полученный в результате решения задачи (2), вообще говоря, не принадлежит множеству Парето.
, полученный в результате решения задачи (2), вообще говоря, не принадлежит множеству Парето.
Ограничимся случаем, когда множество достижимости ![]() задачи (1) является выпуклым. В этом случае при каждом
задачи (1) является выпуклым. В этом случае при каждом ![]() решение задачи (2) единственно, и это решение ставит в соответствие каждому из допустимых векторов
решение задачи (2) единственно, и это решение ставит в соответствие каждому из допустимых векторов ![]() единственный вектор
единственный вектор ![]() , а также соответствующие значения частных критериев оптимальности
, а также соответствующие значения частных критериев оптимальности ![]() [1]. Данное обстоятельство позволяет полагать, что в этом случае функция предпочтений ЛПР определена не на множестве
[1]. Данное обстоятельство позволяет полагать, что в этом случае функция предпочтений ЛПР определена не на множестве ![]() , а на множестве
, а на множестве ![]() :
:
![]() .
.
В результате МКО-задача сводится к задаче выбора вектора ![]() такого, что
такого, что
![]() ,
, ![]() . (3)
. (3)
Поскольку обычно ![]() , переход от задачи (1) к задаче (3) важен с точки зрения уменьшения вычислительных затрат.
, переход от задачи (1) к задаче (3) важен с точки зрения уменьшения вычислительных затрат.
Если используется аддитивная свертка и множество достижимости ![]() является выпуклым, то выражение (2) задает взаимно однозначное отображение множества
является выпуклым, то выражение (2) задает взаимно однозначное отображение множества ![]() на фронт Парето задачи
на фронт Парето задачи ![]() [1]. При этом, как отмечалось, для любого
[1]. При этом, как отмечалось, для любого ![]() вектор
вектор ![]() , являющийся решением задачи (2), принадлежит множеству Парето
, являющийся решением задачи (2), принадлежит множеству Парето ![]() .
.
Отметим, что если вместо аддитивной свертки используется свертка Джоффриона, то взаимно однозначное отображение множества ![]() на множество
на множество ![]() имеет место и в случае, когда множество достижимости
имеет место и в случае, когда множество достижимости ![]() не является выпуклым [6].
не является выпуклым [6].
Величину ![]() будем считать лингвистической переменной со значениями от «Очень-очень плохо» до «Отлично». Ядро нечеткой переменной
будем считать лингвистической переменной со значениями от «Очень-очень плохо» до «Отлично». Ядро нечеткой переменной ![]() обозначим
обозначим ![]() [7], так что значению переменной
[7], так что значению переменной ![]() «Очень-очень плохо» соответствует
«Очень-очень плохо» соответствует ![]() , а значению «Отлично» -
, а значению «Отлично» - ![]() .
.
В результате МКО-задача сводится к задаче отыскания вектора ![]() , обеспечивающего максимальное значение дискретной функции
, обеспечивающего максимальное значение дискретной функции ![]() :
:
![]() ,
, ![]() . (4)
. (4)
2. Метод решения задачи
Общая схема рассматриваемого метода является итерационной и состоит из перечисленных ниже следующих основных этапов [2].
Этап «разгона» метода. МКО-система некоторым образом (например, случайно) последовательно генерирует ![]() векторов
векторов ![]() и для каждого из этих векторов выполняет следующие действия:
и для каждого из этих векторов выполняет следующие действия:
1) решает ОКО-задачу
![]() ,
, ![]() ,
, ![]() ; (5)
; (5)
2) предъявляет ЛПР найденное решение ![]() , а также соответствующие значение всех частных критериев оптимальности
, а также соответствующие значение всех частных критериев оптимальности ![]() ;
;
3) ЛПР оценивает эти данные и вводит в МКО-систему соответствующее значение своей функции предпочтений ![]() .
.
Первый этап. На основе всех имеющихся в МКО-системе значений ![]() вектора
вектора ![]() и соответствующих оценок функции предпочтений
и соответствующих оценок функции предпочтений ![]() МКО-система выполняет следующие действия:
МКО-система выполняет следующие действия:
1) строит функцию ![]() , аппроксимирующую функцию
, аппроксимирующую функцию ![]() в окрестности точек
в окрестности точек ![]() ;
;
2) отыскивает максимум функции ![]() – решает задачу
– решает задачу
![]() ,
, ![]() ;
;
3) с найденным вектором ![]() решает ОКО-задачу вида (5) – находит вектор параметров и соответствующие значения частных критериев оптимальности, а затем предъявляет их ЛПР; ЛПР оценивает указанные данные и вводит в систему соответствующее значение своей функции предпочтений
решает ОКО-задачу вида (5) – находит вектор параметров и соответствующие значения частных критериев оптимальности, а затем предъявляет их ЛПР; ЛПР оценивает указанные данные и вводит в систему соответствующее значение своей функции предпочтений ![]() .
.
Второй этап. На основе всех имеющихся в системе значений ![]() вектора
вектора ![]() и соответствующих оценок функции предпочтений
и соответствующих оценок функции предпочтений ![]() МКО-система выполняет аппроксимацию функции
МКО-система выполняет аппроксимацию функции ![]() в окрестности точек
в окрестности точек ![]() - строит функцию
- строит функцию ![]() и т.д. по схеме первого этапа до тех пор, пока ЛПР не примет решение о прекращении вычислений.
и т.д. по схеме первого этапа до тех пор, пока ЛПР не примет решение о прекращении вычислений.
На каждой итерации ЛПР может выполнить «откат» с целью изменения введенных ранее оценок своей функции предпочтений [3].
3. Алгоритм и программная реализация метода
Входами системы нечеткого вывода являются значения весов частных критериев оптимальности – нечеткие термы ![]() ,
, ![]() ,
, ![]() . Выходной переменной системы нечеткого вывода является лингвистическая переменная
. Выходной переменной системы нечеткого вывода является лингвистическая переменная ![]() , ядро которой
, ядро которой ![]() принимает значения 1, 2,…, 9.
принимает значения 1, 2,…, 9.
Взаимосвязь между входными и выходными переменными описывается нечеткими правилами вида
ЕСЛИ <значения входных переменных> ТО
<значение выходной переменной> ![]() .
.
Здесь ![]() - коэффициенты определенности (веса нечетких правил), полагающиеся равными 1 в случае их неопределенности.
- коэффициенты определенности (веса нечетких правил), полагающиеся равными 1 в случае их неопределенности.
Совокупность значений указанных нечетких входных переменных, выходных лингвистических переменных, а также правил нечетких продукций образуют нечеткую базу знаний.
Используется схема нечеткого вывода Мамдани, который выполняется за два шага [5]. На первом шаге осуществляется формирование базы знаний и грубая настройка модели ![]() . На втором шаге производится тонкая настройка модели
. На втором шаге производится тонкая настройка модели ![]() , заключающаяся в подборе таких весов нечетких правил
, заключающаяся в подборе таких весов нечетких правил ![]() и таких параметров функций принадлежности, которые минимизируют различие между экспериментальной и желаемой моделями.
и таких параметров функций принадлежности, которые минимизируют различие между экспериментальной и желаемой моделями.
3.1. Шаг 1. Положим, что выполнено ![]() экспериментов по определению значений лингвистической переменной
экспериментов по определению значений лингвистической переменной ![]() . Пусть в
. Пусть в ![]() этих экспериментов переменная
этих экспериментов переменная ![]() приняла значение
приняла значение ![]() , в
, в ![]() опытах - значение
опытах - значение ![]() и т.д. до
и т.д. до ![]() и
и ![]() . Соответствующие входные векторы
. Соответствующие входные векторы ![]() обозначим
обозначим ![]() , где
, где ![]() ,
, ![]() .
.
Матрицу знаний ![]() можно представить в виде следующей системы логических высказываний
можно представить в виде следующей системы логических высказываний
ЕСЛИ ![]() и
и ![]() и … и
и … и ![]() или
или
![]() и
и ![]() и … и
и … и ![]() или
или
……….
![]() и
и ![]() и … и
и … и ![]() ,ТО
,ТО ![]() .
.
С использованием операций объединения и пересечения множеств эта система высказываний может быть переписана в более компактном виде
![]() ,
, ![]() .
.
Во введенных обозначениях нечеткий логический вывод включает в себя следующие операции [5].
1). Фазификация. Для данного вектора ![]() определяем значение многомерной функции принадлежности
определяем значение многомерной функции принадлежности

где ![]() - веса нечетких правил;
- веса нечетких правил; ![]() - символы логических операций ИЛИ, И;
- символы логических операций ИЛИ, И; ![]() - функция принадлежности весового множителя
- функция принадлежности весового множителя ![]() терму
терму ![]() . Веса
. Веса ![]() определяются с помощью модифицированного правила экспоненциального возрастания весов:
определяются с помощью модифицированного правила экспоненциального возрастания весов: ![]() . Здесь
. Здесь ![]() - свободный параметр алгоритма, а величина
- свободный параметр алгоритма, а величина ![]() находится из условия
находится из условия ![]() .
.
2). Агрегирование - определение степени истинности условий по каждому из правил системы нечеткого вывода. При вычислении значений функции принадлежности ![]() в качестве операций “И”, “ИЛИ”, “импликация” используем операции min, max, prod соответсвенно.
в качестве операций “И”, “ИЛИ”, “импликация” используем операции min, max, prod соответсвенно.
3). Активизация - нахождение степени истинности каждого из подзаключений правил нечетких продукций.
4). Аккумуляция - нахождение функции принадлежности для каждой из выходных лингвистических переменных.
5). Дефаззификация - нахождение обычного (не нечеткого) значения для каждой из выходных лингвистических переменных. Дефаззификация выполняется методом центра тяжести.
3.2. Шаг 2. Тонкая настройка модели ![]() (параметрическая идентификация модели) осуществляется путем подбора следующих параметров:
(параметрическая идентификация модели) осуществляется путем подбора следующих параметров:
· полуширина ![]() функций принадлежности входных переменных
функций принадлежности входных переменных ![]() ;
;
· полуширина ![]() функций принадлежности выходных переменных
функций принадлежности выходных переменных ![]() ;
;
· величина ![]() , определяющая закон изменения весовых множителей
, определяющая закон изменения весовых множителей ![]() .
.
Область допустимых значений указанных параметров представляет собой гиперпараллелепипед
![]() ,
, ![]() ,
, ![]() .
.
В качестве критерия оптимальности параметров ![]() используется критерий
используется критерий
 ,
, ![]() ,
,
где ![]() - экспериментальное выходное значение нечеткой модели в точке
- экспериментальное выходное значение нечеткой модели в точке ![]() (т.е. результат нечеткого логического вывода Мамдани в этой точке).
(т.е. результат нечеткого логического вывода Мамдани в этой точке).
Таким образом, формально задача параметрической идентификации формулируется в виде следующей задачи глобальной многомерной условной оптимизации [2]
![]() ,
, ![]() . (6)
. (6)
Вообще говоря, задача (6) должна решаться на каждой итерации рассматриваемого метода (п. 2).
Замечание. Для параметрической идентификации модели ![]() на этапе «разгона» метода может быть использована дополнительная тестовая выборка из некоторого количества допустимых векторов
на этапе «разгона» метода может быть использована дополнительная тестовая выборка из некоторого количества допустимых векторов ![]() . Однако такой подход требует от ЛПР принятия значительного количества «лишних» решений и в данной работе не рассматривается.
. Однако такой подход требует от ЛПР принятия значительного количества «лишних» решений и в данной работе не рассматривается.
3.3. Программная реализация метода. Метод реализован в виде MatLab [7-9] программы PREP-FAZZY. Для решения задач (2), (3), (6) программа использует метод последовательного квадратичного программирования SQP, в котором градиенты целевой функции вычисляются численно с использованием конечных разностей этой функции. Поскольку, как отмечалось выше, все указанные задачи являются, вообще говоря, многоэкстремальными, используется комбинация SQP-метода с методом мультистарта: при решении задач (2), (3) используется 100 случайных начальных точек, равномерно распределенных в областях ![]() ,
, ![]() соответственно; при решении задачи (6) – 30 аналогичных случайных точек, равномерно распределенных в области
соответственно; при решении задачи (6) – 30 аналогичных случайных точек, равномерно распределенных в области ![]() .
.
В качестве критерия окончания поиска в SQP-методе используется относительный критерий вида
![]() ,
,
где ![]() – конечное допустимое положительное отклонение по значению минимизируемой функции
– конечное допустимое положительное отклонение по значению минимизируемой функции ![]() .
.
4. Оценка эффективности метода
Исследование выполнено для двух двумерных двухкритериальных задач и одной двумерной трехкритериальной тестовых МКО-задач:
- двухкритериальная задача 1, имеющая выпуклый фронт Парето,
![]() ;
; ![]() ;
; ![]() ;
;
- двухкритериальная задача 2 (невыпуклый фронт Парето) [10]
![]() ;
; 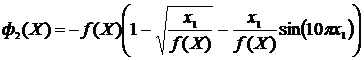 ;
;
![]() ;
; ![]() ;
;
- трехкритериальная задача 3 (выпуклый фронт Парето)
![]() ;
; ![]() ;
;
![]() ;
; ![]() .
.
Использовались нормированные частные критерии оптимальности
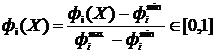 ,
,
где ![]() ,
, ![]() ;
; ![]() ,
, ![]() .
.
Приняты следующие обозначения:
![]() ,
, ![]() ,
, ![]() - времена решения задач (2), (3), (6) соответственно;
- времена решения задач (2), (3), (6) соответственно;
![]() - прочее время;
- прочее время;
![]() - время выполнения одной итерации метода;
- время выполнения одной итерации метода; ![]() =
=![]() +
+![]() +
+![]() +
+![]() .
.
Эксперименты выполнены на персональном компьютере, имеющем следующие значения основных параметров: процессор - IntelCore2 DuoE8400, 3.00 Ггерц, оперативная память - 2.00 Гбайт.
4.1. МКО-задача 1. Критериальное множество МКО-задачи 1 представлено на рис. 1. Исследование выполнено для ![]() «разгонных» значений
«разгонных» значений ![]() вектора
вектора ![]() . В процессе экспериментов ЛПР полагало, что «отличным» значениям его функции предпочтений соответствуют следующие значения критериев оптимальности:
. В процессе экспериментов ЛПР полагало, что «отличным» значениям его функции предпочтений соответствуют следующие значения критериев оптимальности: ![]() ,
, ![]() .
.
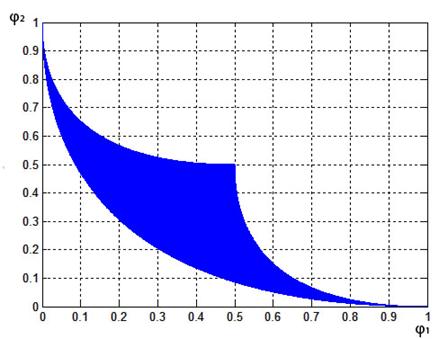
Рис. 1. Множество достижимости ![]() МКО-задачи 1
МКО-задачи 1
При ![]() «разгонных» точках решение задачи потребовало 12 итераций (здесь и далее в число итераций включаются и «разгонные» итерации). Процесс решения задачи иллюстрирует таблица 1, где
«разгонных» точках решение задачи потребовало 12 итераций (здесь и далее в число итераций включаются и «разгонные» итерации). Процесс решения задачи иллюстрирует таблица 1, где ![]() - номер итерации, серым цветом выделены «разгонные» итерации;
- номер итерации, серым цветом выделены «разгонные» итерации; ![]() .
.
Вид функции ![]() после 12 итераций представляет рис. 2. Здесь и далее светлые кружки соответствуют значениям функции предпочтений ЛПР на промежуточных итерациях метода, а темный кружок – на последней итерации.
после 12 итераций представляет рис. 2. Здесь и далее светлые кружки соответствуют значениям функции предпочтений ЛПР на промежуточных итерациях метода, а темный кружок – на последней итерации.
Таблица 1. Результаты решения МКО-задачи 1 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.01 | 0.96 | 0.00 | 1 | 1.35 |
|
|
|
|
2 | 0.68 | 0.09 | 0.47 | 6 | 1.19 |
|
|
|
|
3 | 0.89 | 0.01 | 0.80 | 2 | 1.27 |
|
|
|
|
4 | 0.46 | 0.28 | 0.21 | 8 | 1.13 | 14.4 | 1.4 | 17.1 | 0.05 |
5 | 0.35 | 0.41 | 0.12 | 7 | 1.21 | 16.1 | 1.8 | 19.3 | 0.05 |
6 | 0.51 | 0.23 | 0.26 | 8 | 1.15 | 14.9 | 2.4 | 18.7 | 0.13 |
7 | 0.51 | 0.23 | 0.26 | 8 | 1.17 | 24.9 | 2.7 | 29.0 | 0.13 |
8 | 0.52 | 0.22 | 0.27 | 9 | 1.15 | 17.6 | 2.6 | 21.6 | 0.13 |
9 | 0.53 | 0.21 | 0.28 | 9 | 1.16 | 24.2 | 3.2 | 28.9 | 0.82 |
10 | 0.55 | 0.19 | 0.30 | 9 | 1.15 | 22.7 | 3.0 | 27.2 | 1.02 |
11 | 0.57 | 0.18 | 0.32 | 8 | 1.19 | 27.6 | 3.6 | 32.8 | 1.15 |
12 | 0.54 | 0.21 | 0.29 | 9 | 1.15 | 30.8 | 4.4 | 36.96 | 1.26 |

Рис. 2. Функция предпочтений ЛПР ![]() :
:
МКО-задача 1; число «разгонных » точек ![]() ; 12-я итерация
; 12-я итерация
При ![]() «разгонных» точках решение задачи потребовало 16 итераций. Процесс решения задачи иллюстрирует таблица 2, а результаты - рис. 3.
«разгонных» точках решение задачи потребовало 16 итераций. Процесс решения задачи иллюстрирует таблица 2, а результаты - рис. 3.
Таблица 2. Результаты решения МКО-задачи 1 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.08 | 0.83 | 0.01 | 2 | 1.2 |
|
|
|
|
2 | 0.13 | 0.74 | 0.01 | 3 | 1.2 |
|
|
|
|
3 | 0.46 | 0.28 | 0.21 | 8 | 1.1 |
|
|
|
|
4 | 0.72 | 0.07 | 0.52 | 6 | 1.1 |
|
|
|
|
5 | 0.61 | 0.14 | 0.37 | 8 | 1.1 |
|
|
|
|
6 | 0.43 | 0.32 | 0.18 | 7 | 1.1 | 15.2 | 2.3 | 18.8 | 0.54 |
7 | 0.57 | 0.18 | 0.32 | 8 | 1.1 | 18.8 | 2.8 | 23.0 | 0.82 |
8 | 0.56 | 0.18 | 0.32 | 8 | 1.3 | 19.1 | 2.8 | 23.5 | 0.82 |
9 | 0.81 | 0.03 | 0.66 | 4 | 1.2 | 21.4 | 3.1 | 26.0 | 0.82 |
10 | 0.56 | 0.18 | 0.32 | 8 | 1.1 | 26.3 | 4.1 | 31.9 | 0.87 |
11 | 0.56 | 0.18 | 0.32 | 8 | 1.3 | 29.4 | 4.0 | 35.1 | 0.87 |
12 | 0.66 | 0.11 | 0.44 | 7 | 1.1 | 29.1 | 4.3 | 35.0 | 0.87 |
13 | 0.55 | 0.20 | 0.30 | 9 | 1.4 | 31.2 | 5.8 | 38.8 | 0.98 |
14 | 0.54 | 0.20 | 0.29 | 9 | 1.1 | 35.5 | 5.8 | 43.1 | 1.18 |
15 | 0.54 | 0.21 | 0.29 | 9 | 1.2 | 42.5 | 4.9 | 49.2 | 1.32 |
16 | 0.53 | 0.21 | 0.28 | 9 | 1.2 | 41.5 | 4.7 | 47.9 | 1.44 |
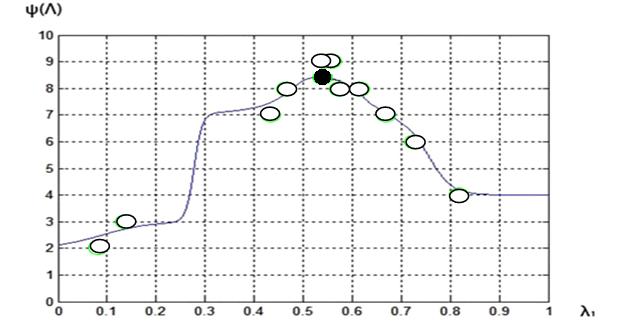
Рис. 3. Функция предпочтений ЛПР ![]() :
:
МКО-задача 1; число «разгонных » точек ![]() ; 16-я итерация
; 16-я итерация
Аналогичные результаты для ![]() «разгонных» точек представлены в таблице 3 и на рис. 4.
«разгонных» точек представлены в таблице 3 и на рис. 4.
Таблица 3. Результаты решения МКО-задачи 1 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.49 | 0.25 | 0.24 | 8 | 1.1 |
|
|
|
|
2 | 0.02 | 0.94 | 0.00 | 1 | 1.3 |
|
|
|
|
3 | 0.99 | 0.00 | 0.98 | 1 | 1.3 |
|
|
|
|
4 | 0.21 | 0.61 | 0.04 | 4 | 1.1 |
|
|
|
|
5 | 0.15 | 0.71 | 0.02 | 3 | 1.2 |
|
|
|
|
6 | 0.61 | 0.15 | 0.37 | 8 | 1.1 |
|
|
|
|
7 | 0.88 | 0.01 | 0.78 | 2 | 1.2 |
|
|
|
|
8 | 0.54 | 0.20 | 0.29 | 9 | 1.4 | 20.1 | 2.6 | 24.4 | 0.45 |
9 | 0.54 | 0.20 | 0.29 | 9 | 1.3 | 25.1 | 8.4 | 35.2 | 0.73 |
10 | 0.54 | 0.20 | 0.29. | 9 | 1.3 | 38.4 | 8.9 | 49.0 | 0.84 |
11 | 0.54 | 0.20 | 0.29 | 9 | 1.2 | 37.1 | 8.7 | 47.4 | 0.92 |
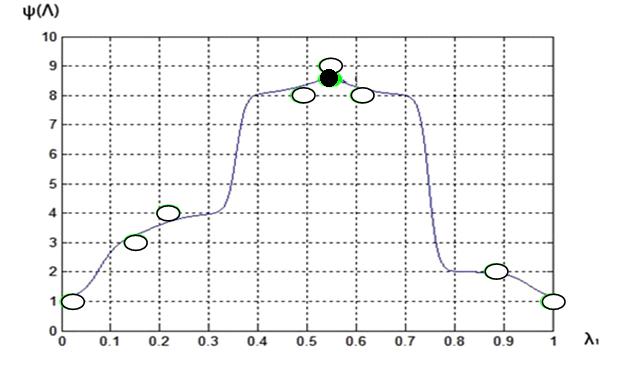
Рис. 4. Функция предпочтений ЛПР ![]() :
:
МКО-задача 1; число «разгонных » точек ![]() ; 11-я итерация
; 11-я итерация
Представляет интерес также характер зависимости времени выполнения одной итерации ![]() от номера итерации (рис. 13).
от номера итерации (рис. 13).
Приведенные результаты исследования показывают, что для первой МКО-задачи аппроксимация функции предпочтений ЛПР с помощью нечеткой логики позволяет быстро найти решение задачи с приемлемой точностью. Так при ![]() «разгонных» точках решение задачи потребовало всего 12 итераций. Увеличение количества «разгонных» точек практически не увеличивает точность решения задачи, а также требуемое количество итераций. Заметим, что решение той же задачи с помощью нейросетевой аппроксимации функции предпочтений ЛПР позволяет найти решение всего за 5 итераций [3].
«разгонных» точках решение задачи потребовало всего 12 итераций. Увеличение количества «разгонных» точек практически не увеличивает точность решения задачи, а также требуемое количество итераций. Заметим, что решение той же задачи с помощью нейросетевой аппроксимации функции предпочтений ЛПР позволяет найти решение всего за 5 итераций [3].
4.2. МКО-задача 2. Критериальное множество МКО-задачи 2 представлено на рис. 5.
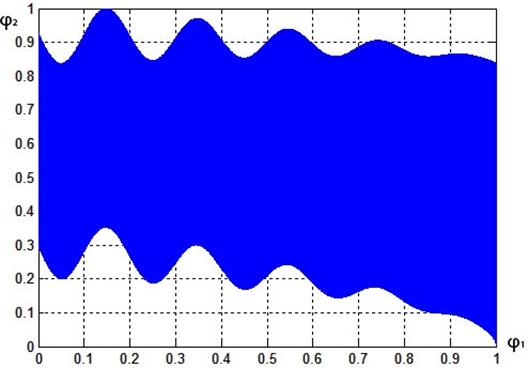
Рис. 5. Множество достижимости ![]() МКО-задачи 2
МКО-задачи 2
Исследование также выполнено для ![]() «разгонных» значений вектора
«разгонных» значений вектора ![]() . В процессе экспериментов ЛПР полагало, что «отличным» значениям его функции предпочтений соответствуют следующие значения критериев оптимальности:
. В процессе экспериментов ЛПР полагало, что «отличным» значениям его функции предпочтений соответствуют следующие значения критериев оптимальности: ![]() ,
, ![]() .
.
При ![]() «разгонных» точках решение задачи потребовало 14 итераций. Процесс решения задачи иллюстрирует таблица 4, а результат решения – рис. 6.
«разгонных» точках решение задачи потребовало 14 итераций. Процесс решения задачи иллюстрирует таблица 4, а результат решения – рис. 6.
Аналогичные результаты для ![]() и
и ![]() «разгонных» точек приведены в таблицах 5, 6 и на рисунках 7, 8.
«разгонных» точек приведены в таблицах 5, 6 и на рисунках 7, 8.
Таблица 4. Результаты решения МКО-задачи 2 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.86 | 0.00 | 0.29 | 1 | 1.7 | 0 | 0 | 0 |
|
2 | 0.74 | 0.01 | 0.26 | 7 | 2.0 | 0 | 0 | 0 |
|
3 | 0.37 | 0.04 | 0.19 | 7 | 1.3 | 0 | 0 | 0 |
|
4 | 0.20 | 0.04 | 0.19 | 7 | 1.4 | 11.4 | 1.1 | 14.3 | 0.05 |
5 | 0.05 | 1.00 | 0.00 | 1 | 1.4 | 13.5 | 1.0 | 16.3 | 0.05 |
6 | 0.45 | 0.04 | 0.20 | 8 | 1.4 | 14.5 | 1.0 | 17.2 | 0.08 |
7 | 0.54 | 0.03 | 0.20 | 8 | 1.6 | 17.7 | 1.2 | 20.9 | 0.08 |
8 | 0.54 | 0.03 | 0.20 | 8 | 1.5 | 19.5 | 1.3 | 22.8 | 0.08 |
9 | 0.57 | 0.03 | 0.20 | 8 | 1.6 | 21.0 | 1.3 | 24.4 | 0.08 |
10 | 0.56 | 0.03 | 0.20 | 8 | 1.6 | 23.1 | 1.3 | 26.4 | 0.08 |
11 | 0.64 | 0.02 | 0.21 | 9 | 1.7 | 26.0 | 2.5 | 30.7 | 0.65 |
12 | 0.66 | 0.02 | 0.22 | 9 | 1.7 | 32.2 | 1.8 | 36.3 | 0.10 |
13 | 0.66 | 0.02 | 0.21 | 9 | 1.7 | 36.3 | 1.8 | 40.4 | 0.11 |
14 | 0.66 | 0.02 | 0.22 | 9 | 1.8 | 33.8 | 1.9 | 38.2 | 0.13 |

Рис. 6. Функция предпочтений ЛПР ![]() :
:
МКО-задача 2; число «разгонных » точек ![]() ; 14-я итерация
; 14-я итерация
Таблица 5. Результаты решения МКО-задачи 2 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.26 | 0.04 | 0.19 | 7 | 1.4 |
|
|
|
|
2 | 0.96 | 0.00 | 0.29 | 1 | 1.0 |
|
|
|
|
3 | 0.45 | 0.04 | 0.20 | 8 | 1.5 |
|
|
|
|
4 | 0.09 | 1.00 | 0.00 | 1 | 1.4 |
|
|
|
|
5 | 0.67 | 0.02 | 0.22 | 9 | 1.8 |
|
|
|
|
6 | 0.70 | 0.02 | 0.23 | 9 | 1.8 | 14.7 | 1.4 | 18.1 | 0.09 |
7 | 0.77 | 0.00 | 0.29 | 1 | 1.9 | 16.9 | 1.2 | 20.4 | 0.11 |
8 | 0.61 | 0.03 | 0.21 | 8 | 1.7 | 22.1 | 1.3 | 25.6 | 0.17 |
9 | 0.68 | 0.02 | 0.22 | 9 | 1.8 | 21.6 | 1.6 | 25.6 | 0.18 |
10 | 0.68 | 0.02 | 0.22 | 9 | 1.8 | 31.4 | 1.6 | 35.3 | 0.19 |
11 | 0.68 | 0.02 | 0.22 | 9 | 1.8 | 28.4 | 1.7 | 32.5 | 0.20 |
12 | 0.68 | 0.02 | 0.22 | 9 | 1.9 | 35.6 | 1.6 | 39.7 | 0.20 |
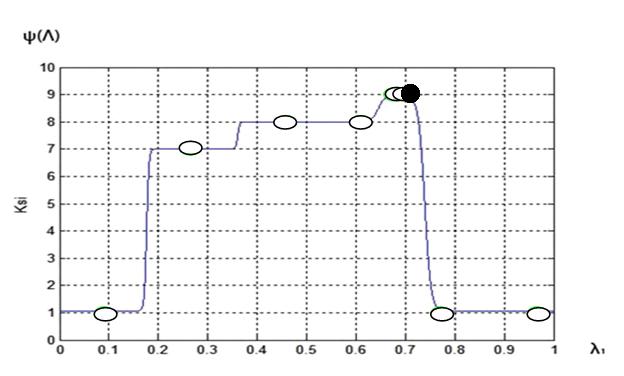
Рис. 7. Функция предпочтений ЛПР ![]() :
:
МКО-задача 2; число «разгонных » точек ![]() ; 12-я итерация
; 12-я итерация
Таблица 6. Результаты решения МКО-задачи 2 (![]() )
)
|
|
|
|
|
|
|
|
|
|
1 | 0.43 | 0.04 | 0.20 | 8 | 1.5 |
|
|
|
|
2 | 0.95 | 0.00 | 0.29 | 1 | 1.2 |
|
|
|
|
3 | 0.32 | 0.04 | 0.19 | 7 | 1.4 |
|
|
|
|
4 | 0.71 | 0.01 | 0.24 | 8 | 1.7 |
|
|
|
|
5 | 0.09 | 1.00 | 0.00 | 1 | 1.4 |
|
|
|
|
6 | 0.90 | 0.00 | 0.29 | 1 | 1.6 |
|
|
|
|
7 | 0.59 | 0.03 | 0.21 | 8 | 1.6 |
|
|
|
|
8 | 0.62 | 0.03 | 0.21 | 8 | 1.9 | 18.8 | 1.2 | 22.3 | 0.09 |
9 | 0.53 | 0.03 | 0.20 | 8 | 1.5 | 16.7 | 1.2 | 20.0 | 0.09 |
10 | 0.51 | 0.03 | 0.20 | 8 | 1.5 | 20.2 | 1.1 | 23.4 | 0.09 |
11 | 0.55 | 0.03 | 0.20 | 8 | 1.5 | 19.3 | 1.5 | 22.8 | 0.09 |
12 | 0.65 | 0.02 | 0.22 | 9 | 1.7 | 33.1 | 2.2 | 37.7 | 0.45 |
13 | 0.65 | 0.02 | 0.22 | 9 | 1.7 | 39.3 | 2.1 | 43.7 | 0.46 |
14 | 0.65 | 0.02 | 0.22 | 9 | 1.7 | 40.7 | 2.1 | 45.2 | 0.46 |
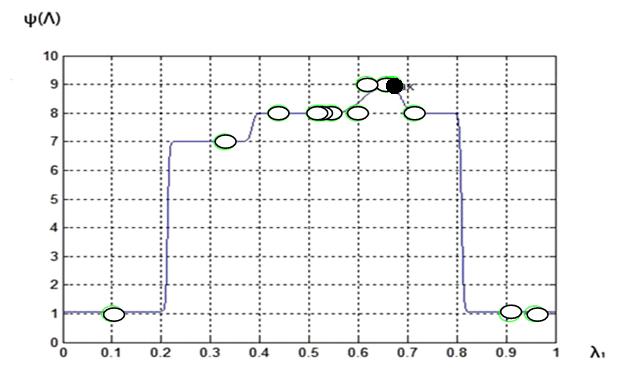
Рис. 8 Функция предпочтений ЛПР ![]() :
:
МКО-задача 2; число «разгонных » точек ![]() ; 14-я итерация
; 14-я итерация
Характер зависимости времени выполнения одной итерации ![]() от номера итерации иллюстрирует рис. 13.
от номера итерации иллюстрирует рис. 13.
Результаты исследования показывают, что для второй МКО-задачи аппроксимация функции предпочтений ЛПР с помощью нечеткой логики позволяет найти решение задачи с приемлемой точностью за 12 – 14 итераций. Так же, как для МКО-задачи 1, увеличение количества «разгонных» точек практически не увеличивает точность решения задачи и требуемое количество итераций.
4.3. МКО-задача 3. Критериальное множество МКО-задачи 3 представлено на рис. 9. Исследование, как и в предыдущих пунктах, выполнено для ![]() «разгонных» значений вектора
«разгонных» значений вектора ![]() .
.
При ![]() «разгонных» точках решение задачи потребовало 17 итераций. Процесс решения задачи иллюстрирует таблица 7. Вид функции
«разгонных» точках решение задачи потребовало 17 итераций. Процесс решения задачи иллюстрирует таблица 7. Вид функции ![]() после 17 итераций представляет рис. 10 (напомним, что
после 17 итераций представляет рис. 10 (напомним, что ![]() ).
).
Аналогично, для ![]() «разгонных» точек потребовалось 11 итераций, а для
«разгонных» точек потребовалось 11 итераций, а для ![]() - 16 итераций. Соответствующие результаты представлены в таблицах 8, 9, а также на рис. 11, 12.
- 16 итераций. Соответствующие результаты представлены в таблицах 8, 9, а также на рис. 11, 12.

Рис. 9. Множество достижимости ![]() МКО-задачи 3
МКО-задачи 3
Таблица 7. Результаты решения МКО-задачи 3 (![]() )
)
|
|
|
|
|
|
|
|
|
|
|
|
1 | 0.31 | 0.23 | 0.24 | 0.29 | 0.15 | 7 | 1.5 |
|
|
|
|
2 | 0.28 | 0.06 | 0.31 | 0.46 | 0.06 | 3 | 1.4 |
|
|
|
|
3 | 0.22 | 0.32 | 0.30 | 0.23 | 0.14 | 8 | 1.5 |
|
|
|
|
4 | 0.16 | 0.83 | 0.45 | 0.01 | 0.57 | 3 | 1.4 | 16.4 | 6.4 | 30.1 | 0.17 |
5 | 0.00 | 0.44 | 0.50 | 0.20 | 0.13 | 2 | 1.3 | 19.6 | 7.3 | 33.4 | 0.17 |
6 | 0.40 | 0.51 | 0.20 | 0.13 | 0.42 | 8 | 1.4 | 20.3 | 12.8 | 39.8 | 0.17 |
7 | 0.00 | 0.00 | 0.00 | 0.65 | 0.65 | 1 | 1.5 | 21.5 | 9.4 | 37.9 | 0.17 |
8 | 0.39 | 0.52 | 0.21 | 0.13 | 0.43 | 8 | 1.4 | 27.1 | 15.6 | 50.2 | 0.21 |
9 | 0.39 | 0.52 | 0.21 | 0.13 | 0.43 | 8 | 1.4 | 27.0 | 14.4 | 49.3 | 0.21 |
10 | 0.38 | 0.44 | 0.20 | 0.16 | 0.34 | 9 | 1.4 | 26.5 | 14.9 | 49.5 | 0.21 |
11 | 0.64 | 0.18 | 0.06 | 0.37 | 0.37 | 4 | 1.4 | 30.3 | 34.1 | 72.4 | 0.52 |
12 | 0.34 | 0.38 | 0.21 | 0.19 | 0.26 | 9 | 1.4 | 33.5 | 37.1 | 78.7 | 0.53 |
13 | 0.22 | 0.50 | 0.31 | 0.12 | 0.27 | 8 | 1.5 | 32.3 | 62.9 | 103.5 | 0.54 |
14 | 0.36 | 0.37 | 0.20 | 0.19 | 0.27 | 9 | 1.4 | 35.1 | 56.9 | 100.4 | 0.55 |
15 | 0.36 | 0.37 | 0.20 | 0.19 | 0.27 | 9 | 1.5 | 38.8 | 35.5 | 82.8 | 0.57 |
16 | 0.36 | 0.37 | 0.20 | 0.19 | 0.27 | 9 | 1.5 | 43.5 | 38.8 | 91.1 | 0.58 |
17 | 0.36 | 0.37 | 0.20 | 0.19 | 0.27 | 9 | 1.4 | 46.7 | 43.3 | 99.0 | 0.59 |

Рис. 10. Линии уровня функции предпочтений ЛПР ![]() :
:
МКО-задача 3; число «разгонных » точек ![]() ; 17-я итерация
; 17-я итерация
Таблица 8. Результаты решения МКО-задачи 3 (![]() )
)
|
|
|
|
|
|
|
|
|
|
|
|
1 | 0.26 | 0.20 | 0.28 | 0.32 | 0.11 | 7 | 1.5 |
|
|
|
|
2 | 0.38 | 0.58 | 0.23 | 0.10 | 0.48 | 7 | 1.3 |
|
|
|
|
3 | 0.28 | 0.11 | 0.29 | 0.40 | 0.08 | 4 | 1.4 |
|
|
|
|
4 | 0.63 | 0.26 | 0.06 | 0.31 | 0.43 | 5 | 1.4 |
|
|
|
|
5 | 0.02 | 0.68 | 0.50 | 0.06 | 0.32 | 3 | 1.3 |
|
|
|
|
6 | 0.39 | 0.60 | 0.24 | 0.10 | 0.50 | 6 | 1.4 | 20.4 | 10.1 | 37.2 | 0.67 |
7 | 0.09 | 0.39 | 0.41 | 0.21 | 0.13 | 2 | 1.4 | 19.0 | 7.6 | 33.6 | 0.94 |
8 | 0.37 | 0.36 | 0.19 | 0.20 | 0.27 | 9 | 1.4 | 17.0 | 17.6 | 41.7 | 0.94 |
9 | 0.36 | 0.39 | 0.20 | 0.18 | 0.29 | 9 | 1.5 | 21.6 | 35.9 | 65.3 | 0.95 |
10 | 0.36 | 0.39 | 0.20 | 0.18 | 0.29 | 9 | 1.5 | 26.5 | 29.5 | 64.1 | 0.95 |
11 | 0.36 | 0.39 | 0.20 | 0.18 | 0.29 | 9 | 1.4 | 31.3 | 25.2 | 64.5 | 0.95 |

Рис. 11. Линии уровня функции предпочтений ЛПР ![]() :
:
МКО-задача 3; число «разгонных » точек ![]() ; 11-я итерация
; 11-я итерация
Таблица 9. Результаты решения МКО-задачи 3 (![]() )
)
|
|
|
|
|
|
|
|
|
|
|
|
1 | 0.01 | 0.25 | 0.51 | 0.35 | 0.04 | 2 | 1.4 |
|
|
|
|
2 | 0.43 | 0.38 | 0.16 | 0.19 | 0.33 | 9 | 1.4 |
|
|
|
|
3 | 0.65 | 0.11 | 0.06 | 0.41 | 0.34 | 4 | 1.5 |
|
|
|
|
4 | 0.32 | 0.03 | 0.28 | 0.48 | 0.07 | 2 | 1.4 |
|
|
|
|
5 | 0.47 | 0.27 | 0.13 | 0.27 | 0.28 | 7 | 1.6 |
|
|
|
|
6 | 0.45 | 0.51 | 0.18 | 0.14 | 0.47 | 8 | 1.5 |
|
|
|
|
7 | 0.83 | 0.03 | 0.01 | 0.55 | 0.48 | 3 | 1.5 |
|
|
|
|
8 | 0.00 | 0.82 | 0.56 | 0.02 | 0.44 | 1 | 1.4 | 17.3 | 14.3 | 39.2 | 0.26 |
9 | 0.13 | 0.45 | 0.37 | 0.16 | 0.19 | 5 | 1.4 | 22.2 | 21.5 | 51.4 | 0.26 |
10 | 0.44 | 0.39 | 0.16 | 0.19 | 0.35 | 9 | 1.4 | 27.2 | 36.4 | 71.4 | 0.26 |
11 | 0.45 | 0.40 | 0.16 | 0.19 | 0.36 | 9 | 1.4 | 27.1 | 35.9 | 71.0 | 0.32 |
12 | 0.45 | 0.40 | 0.16 | 0.19 | 0.36 | 8 | 1.4 | 33.1 | 28.9 | 70.1 | 0.35 |
13 | 0.32 | 0.49 | 0.24 | 0.13 | 0.34 | 9 | 1.4 | 31.1 | 58.7 | 98.1 | 1.19 |
14 | 0.30 | 0.51 | 0.26 | 0.11 | 0.34 | 8 | 1.4 | 37.9 | 46.3 | 92.6 | 1.18 |
15 | 0.31 | 0.39 | 0.23 | 0.18 | 0.25 | 9 | 1.5 | 46.6 | 55.9 | 111.4 | 1.35 |
16 | 0.30 | 0.39 | 0.24 | 0.20 | 0.22 | 9 | 1.4 | 49.2 | 67.5 | 125.4 | 1.34 |
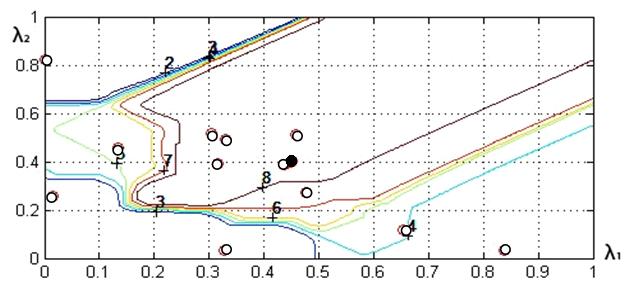
Рис. 12. Линии уровня функции предпочтений ЛПР ![]() :
:
МКО-задача 3; число «разгонных » точек ![]() ; 16-я итерация
; 16-я итерация
Зависимость времени выполнения одной итерации ![]() от номера итерации представлена на рис. 13.
от номера итерации представлена на рис. 13.
Результаты исследования показывают, что для третьей МКО-задачи аппроксимация функции предпочтений ЛПР с помощью нечеткой логики позволяет найти решение задачи за 11 – 17 итераций. Увеличение количества «разгонных» точек мало влияет на точность решения задачи и требуемое количество итераций. Нейросетевая аппроксимация функции предпочтений ЛПР в МКО-задаче 3 позволяет, в лучшем случае, найти решение задачи за 8 итераций (включая 7 «разгонных» итераций).

Рис. 13. Время выполнения одной итерации ![]() как функция номера итерации
как функция номера итерации ![]()
Заключение
Разработан прямой адаптивный метод решения МКО – задачи, основанный на нечеткой аппроксимации функции предпочтений ЛПР. Выполнено исследование эффективности метода, показавшее перспективность его развития. Метод реализован в виде MatLabпрограммы PREF-FUZZY.
Результаты исследования показывают, что для всех трех рассмотренных МКО-задач аппроксимация функции предпочтений ЛПР с помощью нечеткой логики позволяет найти решение задачи не более чем за 17 итераций. При этом увеличение количества «разгонных» точек мало влияет на точность решения задачи и требуемое количество итераций. На каждой итерации большая часть времени уходит на решение задач (4), (6) - на поиск максимума функции предпочтений ЛПР и поиск минимума функции ошибки аппроксимации соответственно. Этот факт объясняется тем, что вычисление значений двух последних функций требует большего количества вычислений на пути
фазификацияàагрегированиеàактивизацияàаккумуляцияàдефаззификация.
К недостаткам метода можно отнести то, что с каждой следующей итерацией вычислительная сложность указанного пути повышается, поскольку увеличивается количество входных правил нечеткой системы.
По сравнению с нейросетевой аппроксимацией функции предпочтений ЛПР, решение задачи с помощью нечеткой логики требует несколько большего количества итераций.
В развитии работы предполагается исследовать эффективность использования сверток ![]() , отличных от рассмотренной в работе аддитивной свертки.
, отличных от рассмотренной в работе аддитивной свертки.
Авторы благодарят Федорука В.Г. за плодотворное обсуждение работы, а также ценные советы по ее совершенствованию.
Литература
1. Лотов, А.В. Введение в экономико-математическое моделирование / А.В.Лотов.– М.: Наука, 1984.- 392 с.
2. Карпенко, А.П. Один класс прямых адаптивных методов многокритериальной оптимизации / А.П.Карпенко, В.Г.Федорук // Информационные технологии.- 2009.- ╧5.- С.24-30.
3. Карпенко, А.П. Нейросетевая аппроксимация функции предпочтений лица, принимающего решения, в задаче многокритериальной оптимизации / А.П.Карпенко, Д.Т.Мухлисуллина, В.А.Овчинниокв // Информационные технологии.- 2010.- (в печати).
4. Мухлисуллина, Д.Т. Исследование погрешности нейросетевой аппроксимации функции предпочтений лица, принимающего решения. [Электронный ресурс] / Д.Т.Мухлисуллина // Электронное научно-техническое издание: наука и образование. - 2009.- ╧12. (http://technomag.edu.ru/).
5. Ротштейн, А.П. Интеллектуальные технологии идентификации: нечеткая логика, генетические алгоритмы, нейронные сети / А.П. Ротштейн.- Винница: УНИВЕРСУМ-Винница, 1999.- 320 с.
6. Штойер, Р. Многокритериальная оптимизация. Теория, вычисления и приложения / Р.Штойер.– М.: Радио и связь, 1992.- 504 с.
7. Леоненков, А. Нечеткое моделирование в среде Matlab и fuzzyTECH / А.Леоненков.- СПб: БХВ-Петербург, 2005.- 719 с.
8. Дьяконов, В.П. MATLAB 7.*/R2006/2007. Самоучитель / В.П.Дьяконов.- М.: ДМК-Пресс, 2008.- 768 с.
9. Трифонов, А.Г. Optimization Toolbox 2.2 Руководство пользователя / А.Г.Трифонов [Электронный ресурс]. (http://matlab.exponenta.ru/optimiz/book_1/index.php).
Публикации с ключевыми словами: нечеткая логика, многокритериальная оптимизация, прямой адаптивный метод
Публикации со словами: нечеткая логика, многокритериальная оптимизация, прямой адаптивный метод
Смотри также:
- Многокритериальная оптимизация автономного электрогидравлического следящего привода прямым адаптивным методом
- Исследование погрешности аппроксимации многомерной функции с помощью нейронных сетей с радиальными базисными функциями
- Информационная модель и основные функции программной системы многокритериальной оптимизации ╚Парето╩
Тематические рубрики:




| Авторы |
| Пресс-релизы |
| Библиотека |
| Конференции |
| Выставки |
| О проекте |
| Телефон: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) |
|
||||
| © 2003-2024 «Наука и образование» Перепечатка материалов журнала без согласования с редакцией запрещена Тел.: +7 (915) 336-07-65 (строго: среда; пятница c 11-00 до 17-00) | |||||